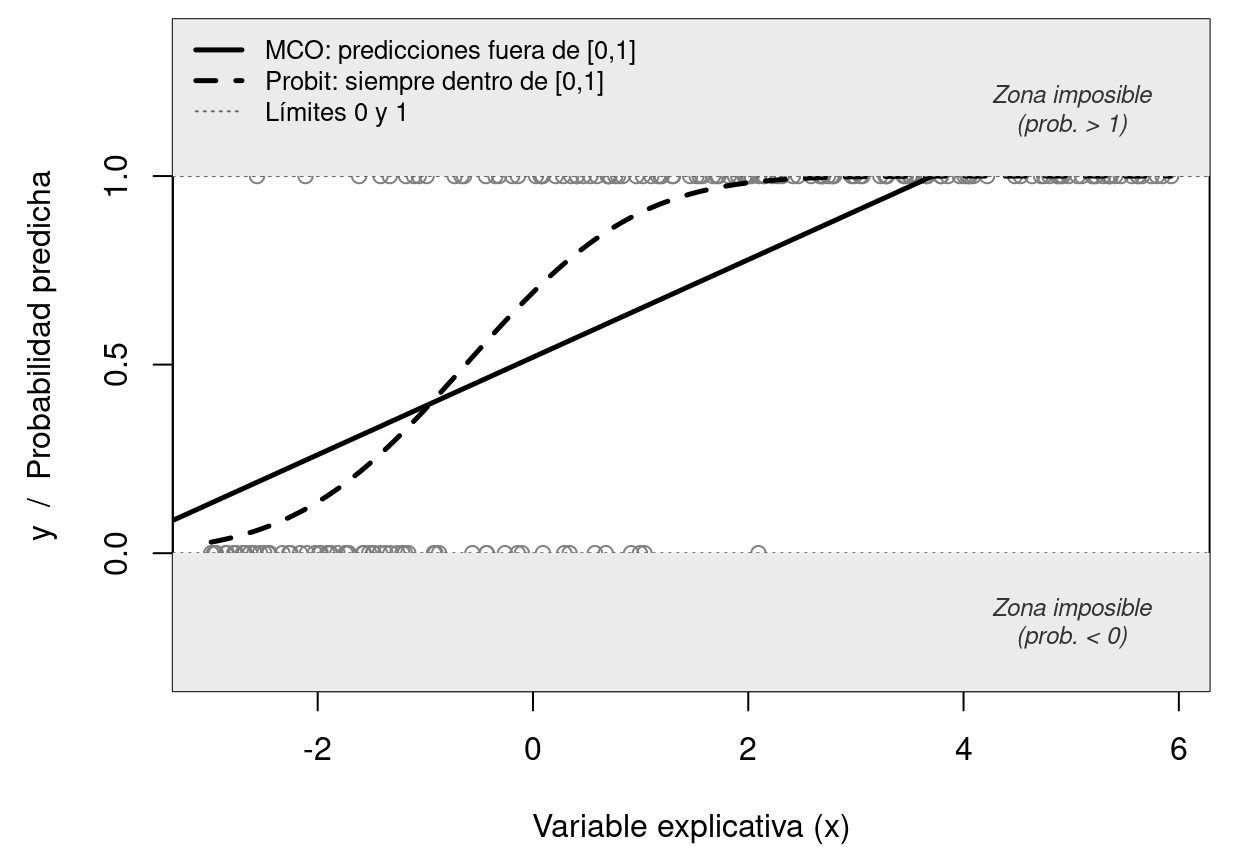
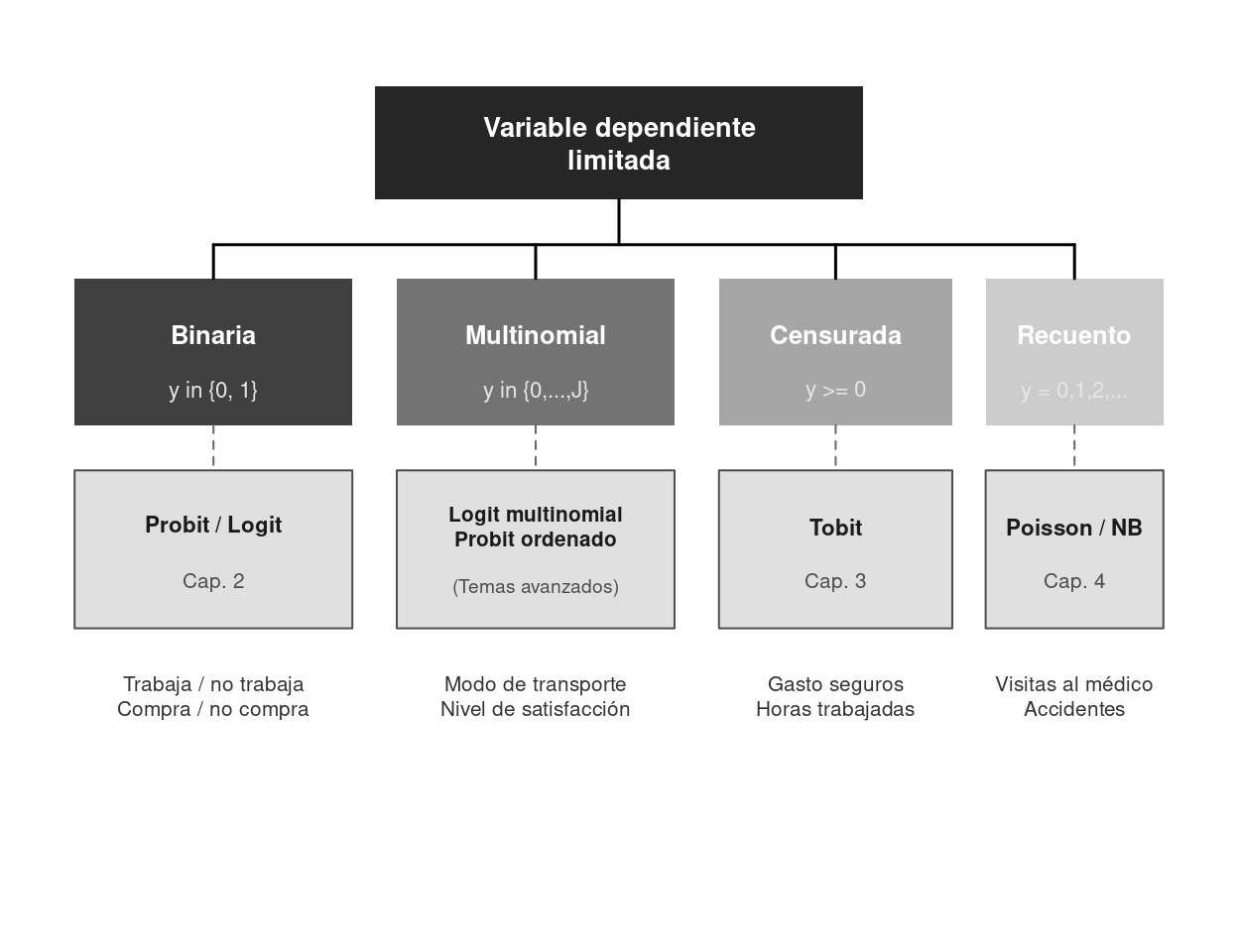
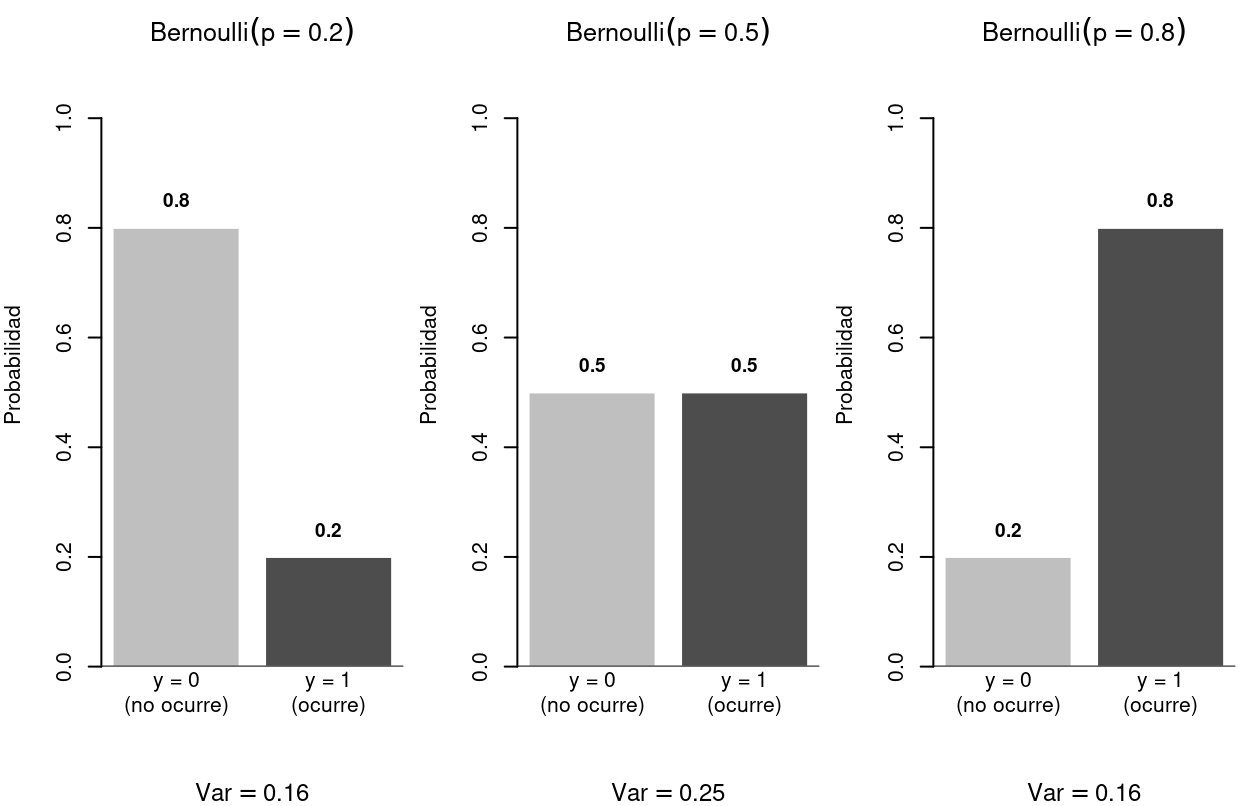
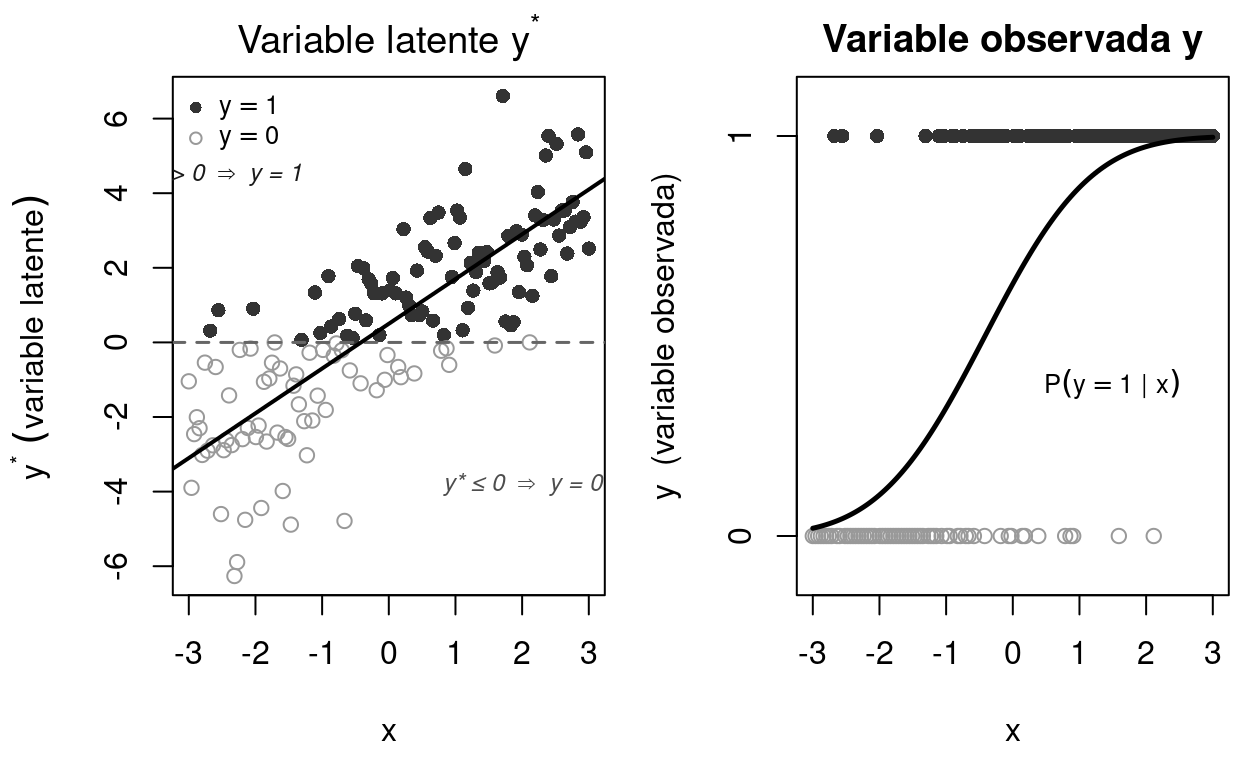
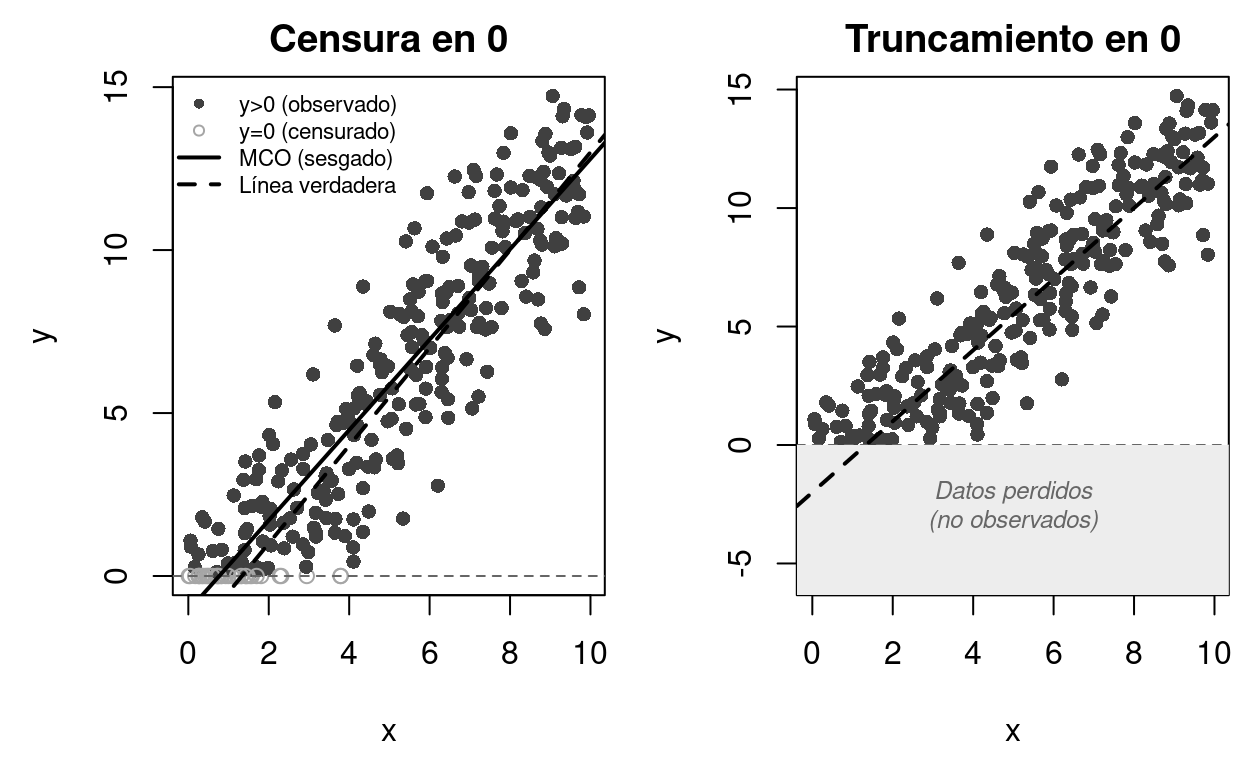
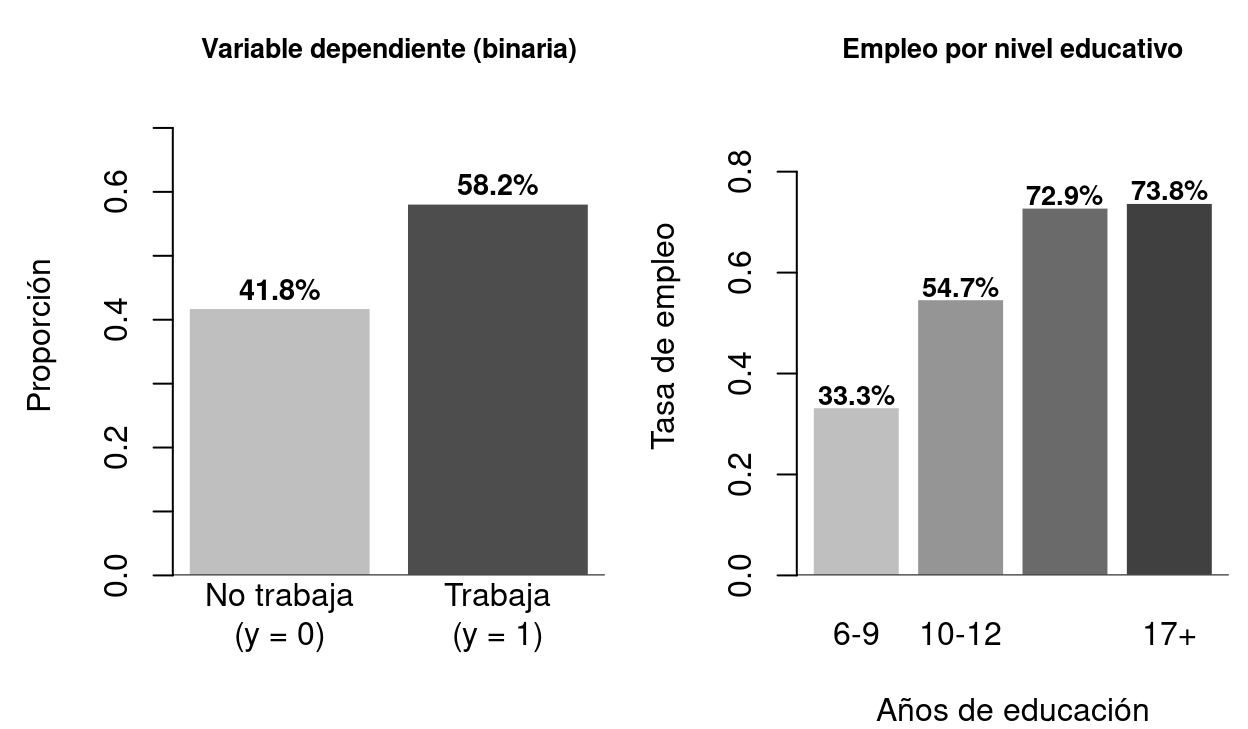
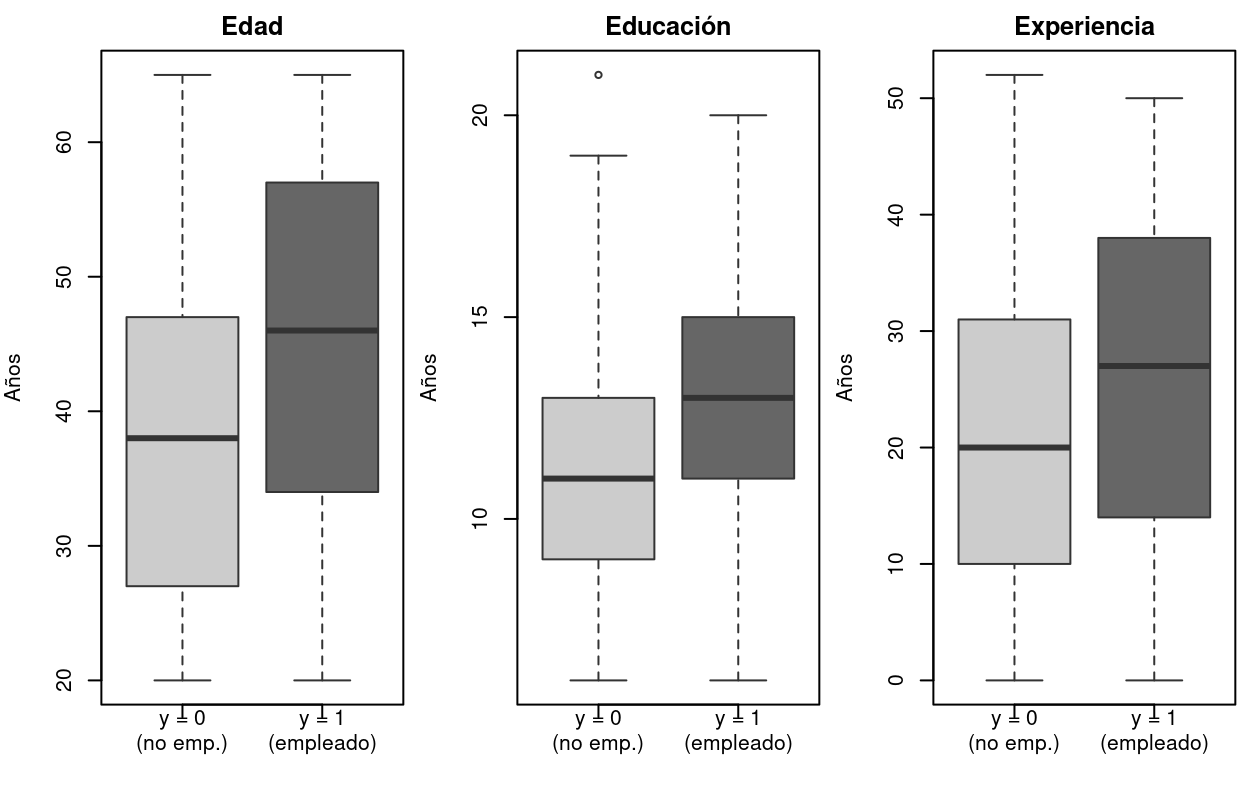
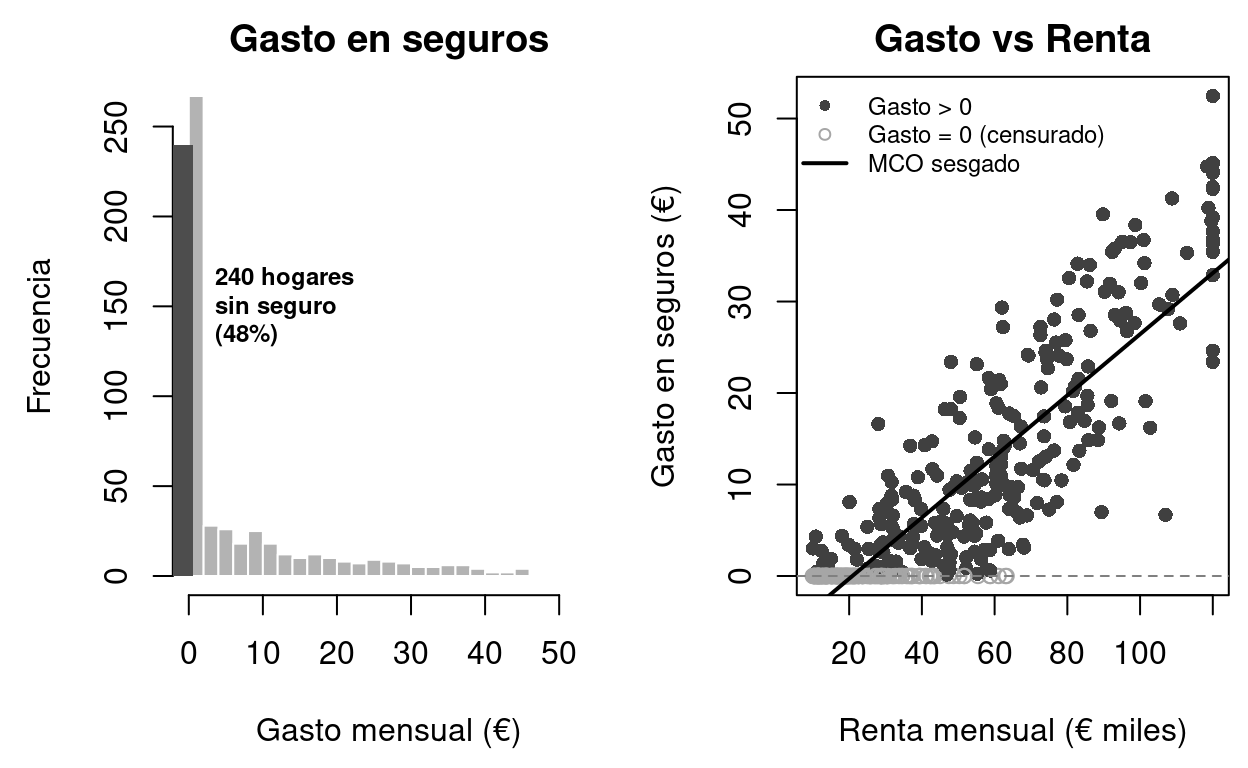
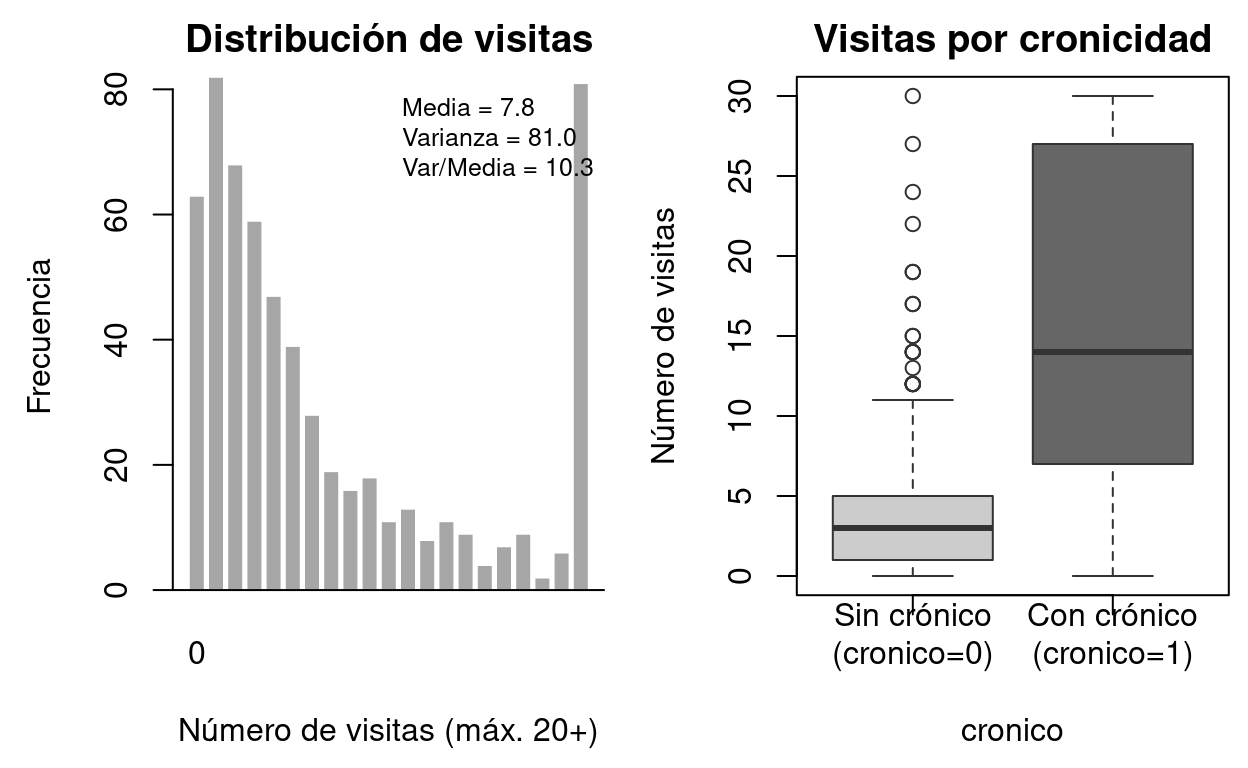
par(mar = c(0.5, 0.5, 0.5, 0.5))
plot(NULL, xlim = c(0, 10), ylim = c(0, 7.5),
xlab = "", ylab = "", xaxt = "n", yaxt = "n", bty = "n")
# Raíz
rect(2.8, 6.2, 7.2, 7.2, col = gray(0.15), border = NA)
text(5, 6.7, "Variable dependiente\nlimitada", col = "white", font = 2, cex = 0.85)
# Ramas
cols_ramas <- gray(c(0.25, 0.45, 0.65, 0.80))
rect(0.1, 4.2, 2.6, 5.5, col = cols_ramas[1], border = NA)
text(1.35, 5.0, "Binaria", col = "white", font = 2, cex = 0.8)
text(1.35, 4.5, "y in {0, 1}", col = gray(0.9), cex = 0.7)
rect(3.0, 4.2, 5.5, 5.5, col = cols_ramas[2], border = NA)
text(4.25, 5.0, "Multinomial", col = "white", font = 2, cex = 0.8)
text(4.25, 4.5, "y in {0,...,J}", col = gray(0.9), cex = 0.7)
rect(5.9, 4.2, 8.0, 5.5, col = cols_ramas[3], border = NA)
text(6.95, 5.0, "Censurada", col = "white", font = 2, cex = 0.8)
text(6.95, 4.5, "y >= 0", col = gray(0.9), cex = 0.7)
rect(8.3, 4.2, 9.9, 5.5, col = cols_ramas[4], border = NA)
text(9.1, 5.0, "Recuento", col = "white", font = 2, cex = 0.8)
text(9.1, 4.5, "y = 0,1,2,...", col = gray(0.9), cex = 0.7)
# Flechas
segments(5, 6.2, 5, 5.8, lwd = 1.5)
segments(1.35, 5.8, 9.1, 5.8, lwd = 1.5)
segments(c(1.35,4.25,6.95,9.1), 5.8, c(1.35,4.25,6.95,9.1), 5.5, lwd=1.5)
# Modelos
rect(0.1, 2.4, 2.6, 3.8, col = gray(0.88), border = gray(0.3), lwd = 1)
text(1.35, 3.3, "Probit / Logit", font = 2, cex = 0.7, col = gray(0.1))
text(1.35, 2.8, "Cap. 2", cex = 0.65, col = gray(0.3))
segments(1.35, 4.2, 1.35, 3.8, lwd=1, lty=2, col=gray(0.4))
rect(3.0, 2.4, 5.5, 3.8, col = gray(0.88), border = gray(0.3), lwd = 1)
text(4.25, 3.3, "Logit multinomial\nProbit ordenado", font = 2, cex = 0.65, col = gray(0.1))
text(4.25, 2.75, "(Temas avanzados)", cex = 0.6, col = gray(0.3))
segments(4.25, 4.2, 4.25, 3.8, lwd=1, lty=2, col=gray(0.4))
rect(5.9, 2.4, 8.0, 3.8, col = gray(0.88), border = gray(0.3), lwd = 1)
text(6.95, 3.3, "Tobit", font = 2, cex = 0.7, col = gray(0.1))
text(6.95, 2.8, "Cap. 3", cex = 0.65, col = gray(0.3))
segments(6.95, 4.2, 6.95, 3.8, lwd=1, lty=2, col=gray(0.4))
rect(8.3, 2.4, 9.9, 3.8, col = gray(0.88), border = gray(0.3), lwd = 1)
text(9.1, 3.3, "Poisson / NB", font = 2, cex = 0.7, col = gray(0.1))
text(9.1, 2.8, "Cap. 4", cex = 0.65, col = gray(0.3))
segments(9.1, 4.2, 9.1, 3.8, lwd=1, lty=2, col=gray(0.4))
# Ejemplos
text(1.35, 1.8, "Trabaja / no trabaja\nCompra / no compra", cex = 0.65, col=gray(0.2))
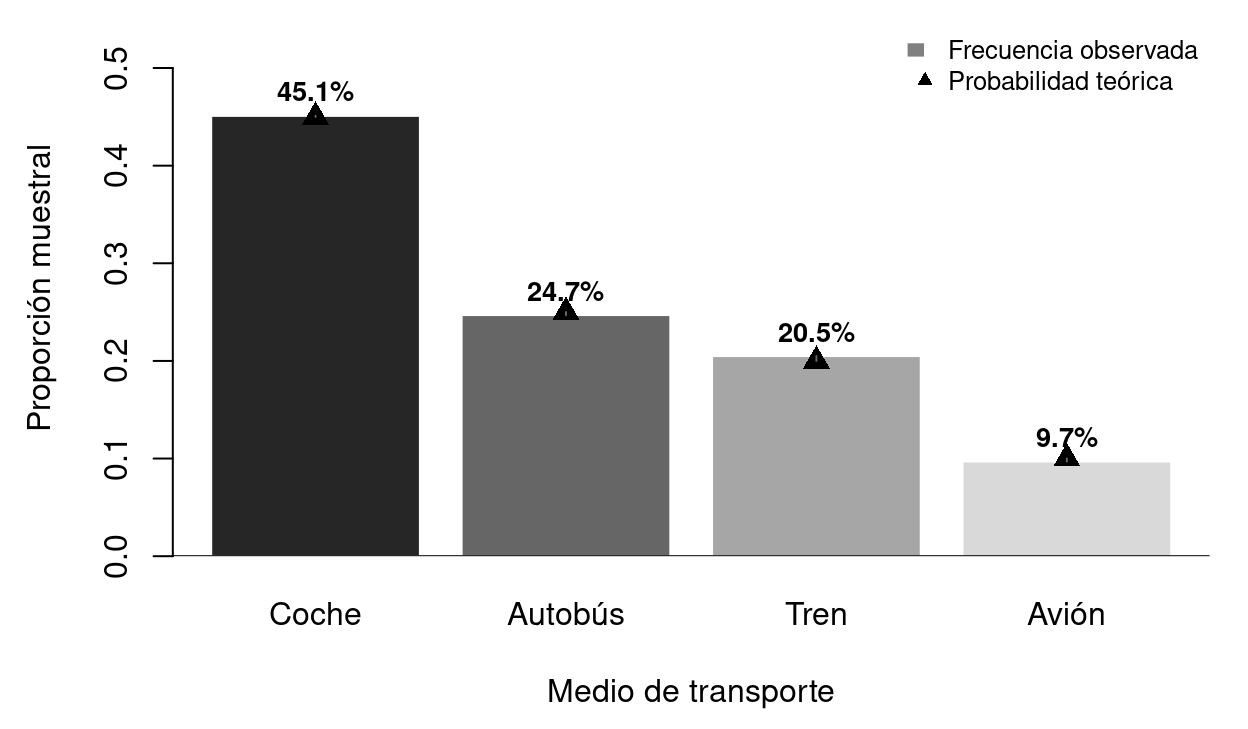
text(4.25, 1.8, "Modo de transporte\nNivel de satisfacción", cex = 0.65, col=gray(0.2))
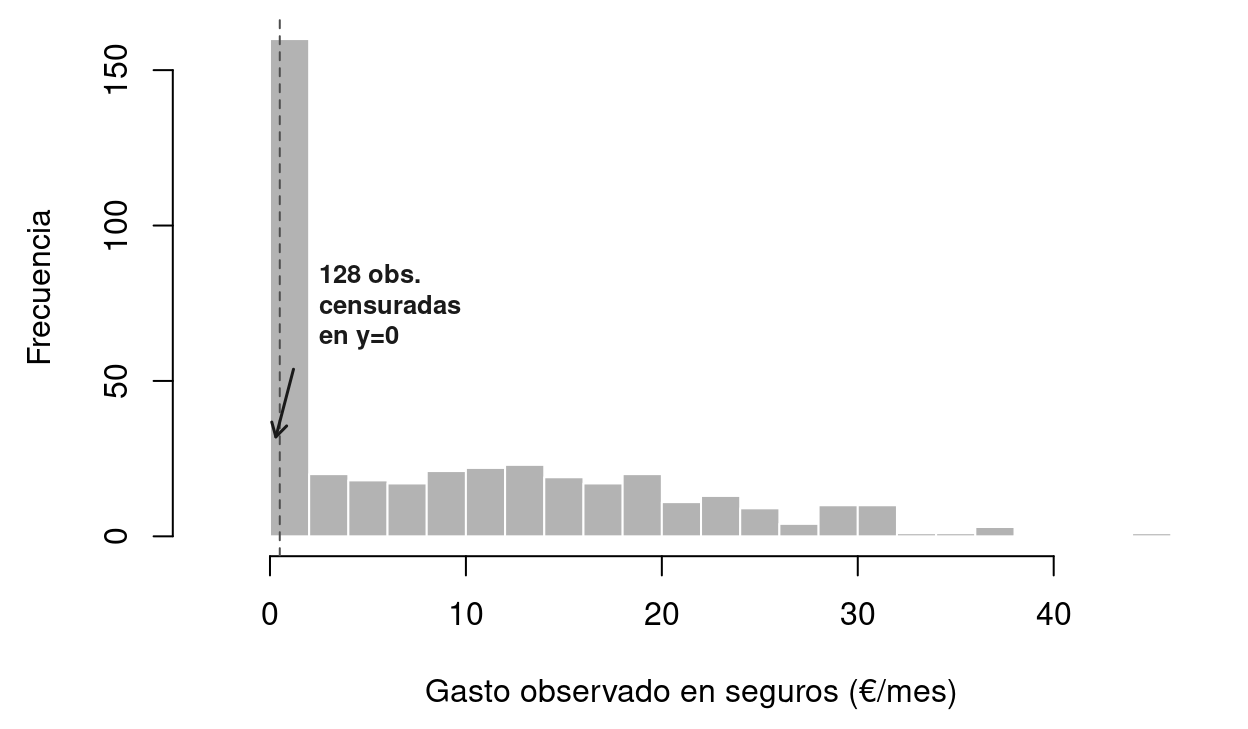
text(6.95, 1.8, "Gasto seguros\nHoras trabajadas", cex = 0.65, col=gray(0.2))
text(9.1, 1.8, "Visitas al médico\nAccidentes", cex = 0.65, col=gray(0.2))