3.1 El problema: variables continuas con restricciones en el rango
Los capítulos anteriores trataron los casos en que la variable dependiente es discreta. Pero hay una familia importante de situaciones en las que \(y_i\) es continua y en principio podría tomar cualquier valor positivo — el gasto mensual en seguros, las donaciones a organizaciones benéficas, las horas de formación — y sin embargo una fracción sustancial de la muestra presenta exactamente el valor cero. Este cero no es un error de medida ni una anomalía: refleja una decisión económica genuina. La familia que no contrata ningún seguro no tiene un gasto negativo en seguros: simplemente no gasta nada porque su “demanda óptima” es nula dado su nivel de renta y sus preferencias.
Estamos ante lo que en el capítulo introductorio definimos como datos censurados por la izquierda: existe una variable latente \(y_i^*\) que representa la “demanda óptima” o el “gasto deseado”, pero cuando esta demanda es no positiva, lo que observamos es el valor de censura \(y_i = 0\). El problema econométrico es que MCO aplicado a los datos observados produce estimaciones sesgadas, porque trata los ceros como si fueran valores reales del proceso continuo subyacente. El modelo Tobit, desarrollado por James Tobin en 1958 (Tobin 1958), resuelve este problema estimando correctamente el mecanismo que genera simultáneamente los ceros y los valores positivos.
3.2 El modelo Tobit tipo I
3.2.1 La estructura del modelo
El modelo Tobit clásico (se le denomina también Tipo I) parte, como el Probit y el Logit, del enfoque de variable latente. Existe un proceso continuo subyacente:
Lo que diferencia al Tobit de los modelos de elección discreta es la regla de observación: en lugar de observar solo si \(y_i^* > 0\) o no, observamos el valor exacto de \(y_i^*\) siempre que sea positivo:
El parámetro \(\sigma\) es la desviación típica del término de error, que también se estima. Esto distingue al Tobit del Probit: en el Probit, \(\sigma\) se normaliza a 1 porque solo observamos la decisión dicotómica; en el Tobit, al observar los valores exactos de \(y_i^*\) cuando es positivo, podemos identificar \(\sigma\) por separado.
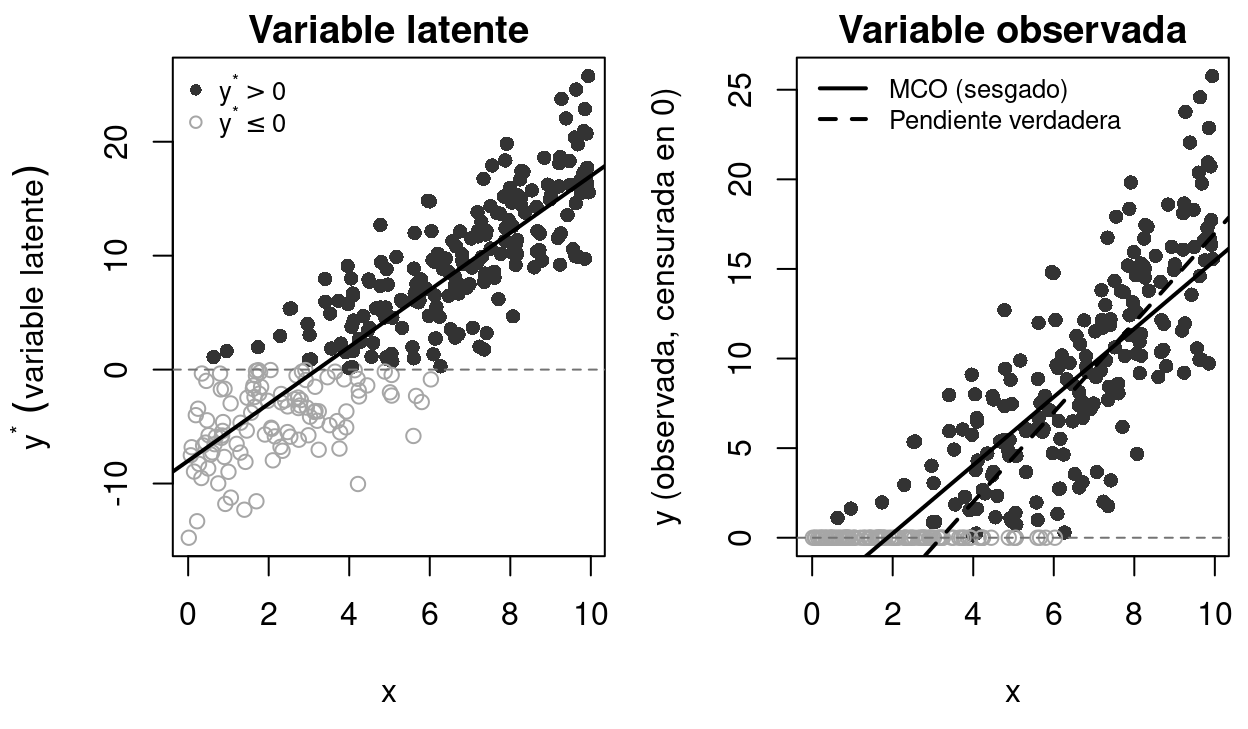
Figure 3.1: Estructura del modelo Tobit. Panel izquierdo: la variable latente y* es continua y puede tomar valores negativos, pero lo que observamos (panel derecho) es y = max(y, 0). Los puntos rellenos corresponden a observaciones con y > 0 y los huecos a los censurados en 0. La recta MCO (línea sólida) queda sesgada respecto a la pendiente verdadera de y* (línea discontinua).
La Figure 3.1 ilustra el sesgo de MCO con datos censurados. En el panel derecho, la recta MCO (sólida) tiene pendiente claramente inferior a la de la relación verdadera (discontinua) porque los ceros “tiran hacia abajo” la estimación.
En el caso del modelo Tobit son clave los supuestos de normalidad, homocedasticidad e independencia del error. A diferencia de MCO, donde la heterocedasticidad causa ineficiencia pero no inconsistencia, en el Tobit la violación de normalidad o homocedasticidad produce inconsistencia. Esto tiene implicaciones directas para el diagnóstico, que desarrollaremos más adelante.
3.2.2 Proporción de censura
Antes de interpretar cualquier resultado, el primer dato que debe calcularse es la proporción de censura de la muestra. Se define como la fracción de observaciones en las que la variable dependiente se encuentra en el límite de censura:
\[\text{Proporción de censura} = \frac{\text{Número de observaciones con } y_i = c}{n}\]
Por ejemplo, si en una muestra de 500 individuos hay 150 con \(y_i = 0\) (horas trabajadas = 0), la proporción de censura es \(150/500 = 0{,}30\) (un 30%). En R, este cálculo es inmediato: mean(datos$y == 0) devuelve directamente la proporción.
Este dato es fundamental porque condiciona la magnitud de la diferencia entre el coeficiente \(\beta_j\) y el efecto marginal sobre la variable observada. Cuanto mayor sea la proporción de censura, mayor será la discrepancia entre ambos, y más imprescindible resulta el cálculo explícito de los efectos marginales.
3.2.3 La reparametrización de Olsen (1978)
La estimación del modelo Tobit por máxima verosimilitud requiere que un algoritmo numérico encuentre los valores de \(\boldsymbol{\beta}\) y \(\sigma\) que maximizan la función \(\ln L(\boldsymbol{\beta}, \sigma)\). A diferencia de MCO, donde existe una fórmula cerrada \((\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}\), en el Tobit no hay solución analítica: la presencia simultánea de \(\Phi(\cdot)\) y \(\phi(\cdot)\) en la log-verosimilitud impide despejar los parámetros. Por tanto, se recurre a métodos iterativos como Newton-Raphson o BFGS, que parten de unos valores iniciales y los van refinando hasta alcanzar el máximo.
En la práctica, la maximización directa con respecto a \((\boldsymbol{\beta}, \sigma)\) puede presentar dificultades numéricas. Los parámetros \(\boldsymbol{\beta}\) y \(\sigma\) operan en escalas muy diferentes (los coeficientes pueden valer 0.5 mientras que \(\sigma\) vale 3), lo que dificulta la convergencia del algoritmo. Además, cuando la proporción de observaciones censuradas es alta o la varianza es pequeña, la superficie de la log-verosimilitud puede ser muy plana en algunas direcciones, provocando que el algoritmo avance lentamente o se detenga antes de alcanzar el óptimo.
Olsen (1978) propuso una transformación que resuelve estas dificultades de forma elegante. En lugar de estimar directamente \((\boldsymbol{\beta}, \sigma)\), se definen dos nuevos parámetros:
La ventaja de esta transformación es que los nuevos parámetros \((\gamma, \lambda)\) operan en escalas más similares entre sí, lo que facilita el trabajo del algoritmo de optimización. La superficie de la log-verosimilitud expresada en términos de \((\gamma, \lambda)\) tiene una curvatura más regular, lo que permite que el algoritmo converja más rápidamente y con mayor estabilidad numérica.
Con esta reparametrización, la log-verosimilitud se reescribe como:
En la práctica, el usuario no necesita preocuparse de esta transformación: los paquetes de software (como censReg o AER en R) la implementan internamente de forma transparente. El usuario especifica el modelo y obtiene directamente las estimaciones de \(\hat{\boldsymbol{\beta}}\) y \(\hat{\sigma}\), ya reconvertidas a la escala original.
Desde una perspectiva histórica, la reparametrización de Olsen fue un avance importante en los años setenta, cuando la capacidad de cálculo era muy limitada. James Tobin había propuesto el modelo en 1958, pero su estimación práctica no fue viable hasta que Olsen resolvió los problemas numéricos. Hoy, aunque los ordenadores son incomparablemente más potentes, la reparametrización sigue siendo el método estándar porque mejora de forma significativa la velocidad y la fiabilidad de la convergencia.
3.2.4 Por qué MCO es inconsistente con datos censurados
El sesgo de MCO no es simplemente un problema de eficiencia que desaparece con muestras grandes: es una inconsistencia. Para verlo, consideremos la esperanza condicional de la variable observada:
donde \(z_i = \mathbf{x}_i'\boldsymbol{\beta}/\sigma\). Esta esperanza es no lineal en \(\mathbf{x}_i\), de modo que el coeficiente que MCO estima converge a una combinación ponderada de los efectos estructurales, no a \(\boldsymbol{\beta}\) directamente. La magnitud del sesgo depende de la fracción de observaciones censuradas: a mayor proporción de ceros, mayor es el sesgo hacia cero de los coeficientes MCO.
3.2.5 La función de verosimilitud del Tobit
La función de verosimilitud del Tobit combina dos componentes: la probabilidad de observar un cero (contribución discreta de las observaciones censuradas) y la densidad de \(y_i\) dado que \(y_i > 0\) (contribución continua de las observaciones no censuradas):
El estimador Tobit \((\hat{\boldsymbol{\beta}}, \hat{\sigma})\) maximiza esta log-verosimilitud. No existe forma cerrada: la maximización es numérica. El estimador es consistente y asintóticamente normal, y en R se obtiene con tobit(y ~ x1 + x2, left=0, data=df) del paquete AER.
3.3 Efectos marginales en el modelo Tobit
Los coeficientes \(\hat{\boldsymbol{\beta}}\) del Tobit tienen una interpretación directa: son los efectos de \(\mathbf{x}_j\) sobre la variable latente\(y^*\). Pero en la mayoría de aplicaciones interesa el efecto sobre la variable observada\(y\). McDonald y Moffitt (1980) demostraron que el efecto marginal sobre \(E[y|\mathbf{x}]\) se descompone de forma elegante:
donde \(z = \mathbf{x}'\boldsymbol{\beta}/\hat{\sigma}\). Esta expresión dice que el efecto marginal sobre el valor esperado observado es el coeficiente \(\beta_j\) atenuado por la probabilidad de que la observación no esté censurada. En los puntos donde casi todas las observaciones son positivas (\(\Phi(z) \approx 1\)), el efecto marginal se aproxima a \(\beta_j\); donde la censura es elevada (\(\Phi(z)\) pequeño), el efecto es mucho menor.
Adicionalmente, McDonald y Moffitt descomponen el efecto total en dos canales:
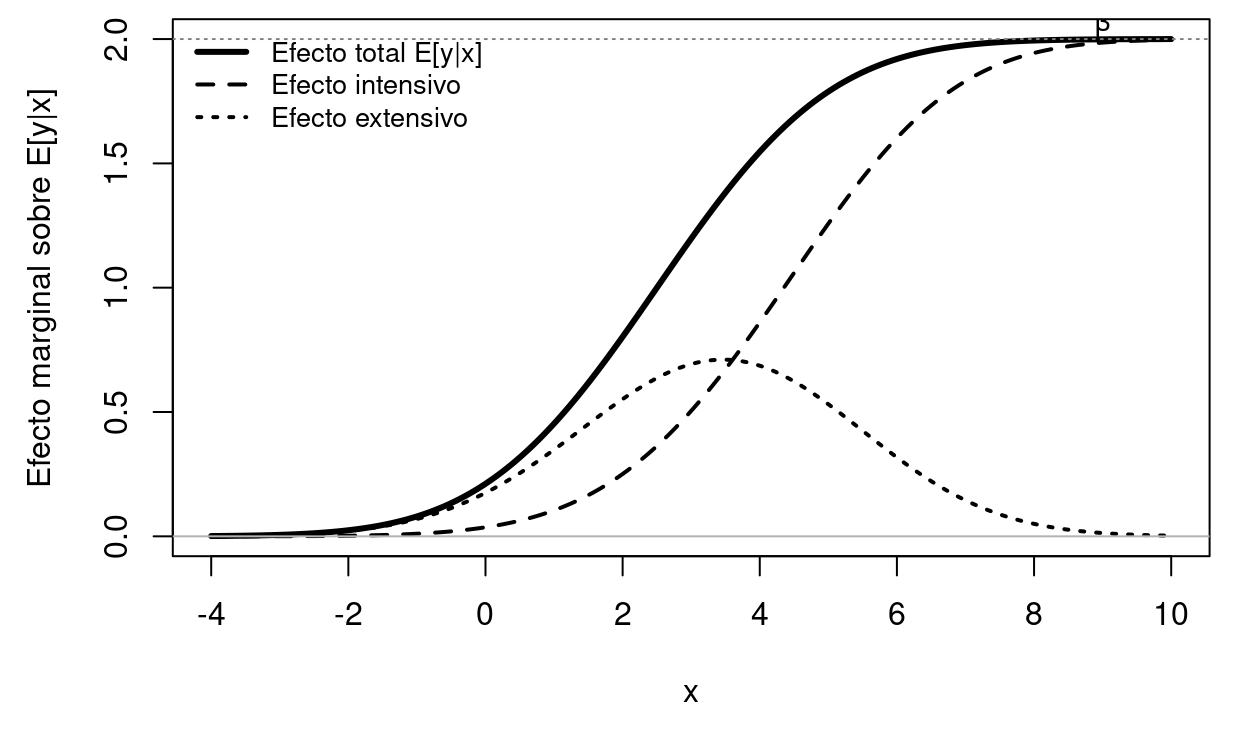
El efecto extensivo captura cómo un cambio en \(x_j\) altera la probabilidad de tener un valor positivo (si aumenta el porcentaje de personas que pasan de cero a positivo). El efecto intensivo captura cómo cambia el nivel esperado dado que ya es positivo. Ambos efectos son siempre del mismo signo que \(\beta_j\).
Figure 3.2: Descomposición de McDonald-Moffitt de los efectos marginales del Tobit. El efecto total sobre E[y|x] (línea sólida gruesa) se compone del efecto intensivo (línea discontinua) y el extensivo (línea punteada). Cuando toda la muestra está por encima del umbral de censura (derecha del gráfico), el efecto total converge al coeficiente beta.
3.4 Modelo ilustrativo: gasto en seguros médicos
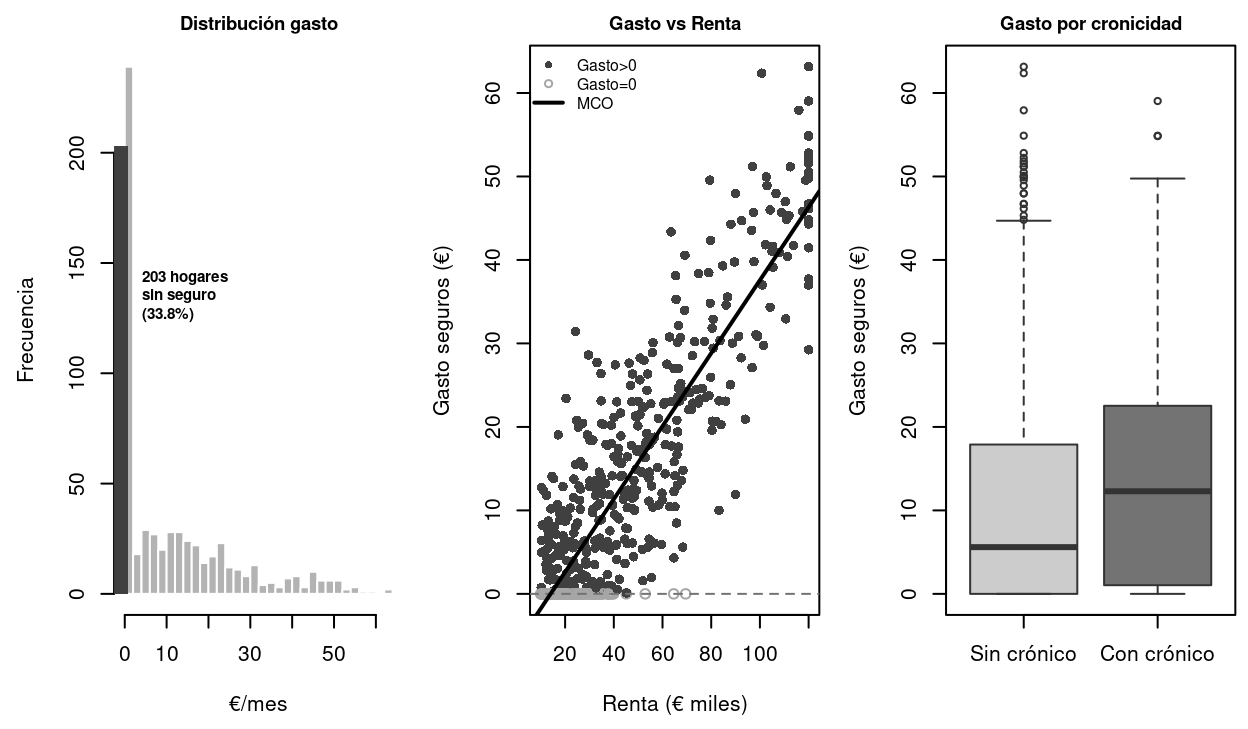
Para desarrollar el análisis completo trabajaremos con el dataset de gasto en seguros médicos privados (T03_CP01_gasto_seguros.RData), que recoge 600 hogares. La variable dependiente gasto_seguros es el gasto mensual en seguros (€), censurada en cero para los hogares sin seguro privado. El 33.8% de los hogares no tiene ningún seguro (gasto = 0). Las covariables son: renta mensual del hogar (€ miles), edad del cabeza de familia, número de miembros, años de educación del cabeza de familia, indicador de zona urbana y presencia de enfermedad crónica.
3.4.1 Análisis exploratorio
Antes de estimar el Tobit es imprescindible diagnosticar la estructura de los datos. La Figure 3.3 muestra los patrones clave.
Figure 3.3: Análisis exploratorio del gasto en seguros. Panel izquierdo: distribución con masa discreta en 0 (33.8% de hogares). Panel central: el gasto crece con la renta, pero la recta MCO subestima la pendiente verdadera por el sesgo de censura. Panel derecho: los hogares con enfermedad crónica gastan considerablemente más en seguros.
3.4.2 Estimación del modelo Tobit y comparación con MCO
Table 3.1: Estimación comparada MCO vs Tobit para el gasto en seguros. Los coeficientes MCO son consistentemente menores que los Tobit porque la censura sesga las estimaciones hacia cero. La diferencia es especialmente marcada en las variables más potentes (renta, cronico).
Variable
MCO
Tobit
Ratio Tobit/MCO
Renta (€m)
0.436***
0.505***
1.16
Edad
0.029
0.038
1.31
Miembros hogar
0.990***
1.499***
1.51
Educ. (años)
0.429***
0.704***
1.64
Zona urbana
2.154***
3.403***
1.58
Crónico
4.195***
5.895***
1.41
Nota:
***p<.001, **p<.01, *p<.05. Tobit: coefs. sobre y*.
La Table 3.1 pone de manifiesto el sesgo de MCO: todos los coeficientes del Tobit son mayores en valor absoluto que los de MCO (ratio > 1). La diferencia es especialmente pronunciada para renta (ratio 1.16) y cronico (ratio 1.41). Cuanto mayor es la proporción de observaciones censuradas, mayor es el sesgo hacia cero de MCO.
Table 3.2: Efectos marginales AME del Tobit (McDonald-Moffitt). Se muestra el efecto sobre E[y|x] (observada), sobre E[y|y>0,x] (condicional en positivo) y la descomposición en efecto intensivo y extensivo.
Variable
AME E[y|x]
AME E[y|y>0]
Intensivo
Extensivo
Renta (€m)
0.340
0.298
0.246
0.094
Edad
0.025
0.022
0.018
0.007
Miembros hogar
1.008
0.884
0.730
0.278
Educ. (años)
0.473
0.415
0.343
0.130
Zona urbana
2.289
2.007
1.658
0.631
Crónico
3.965
3.478
2.872
1.093
Nota:
Valores en €/mes. AME obs. = efecto sobre gasto esperado total.
La Table 3.2 revela que un incremento de €1.000 en la renta mensual aumenta el gasto esperado en seguros en 0.34€/mes (AME sobre \(E[y|\mathbf{x}]\)). La presencia de enfermedad crónica aumenta el gasto esperado en 3.97€/mes. En ambos casos, el efecto extensivo (más hogares contratando seguro) supera al intensivo (mayor gasto entre quienes ya tenían seguro), lo que indica que estas variables operan principalmente a través de la decisión de asegurarse, no tanto del nivel de cobertura contratado.
3.5 Interpretación de los coeficientes: las tres preguntas
En regresión lineal, \(\beta_j\) es el efecto marginal. En el Tobit, no. La censura introduce una no linealidad, y el efecto de \(x_j\) depende de qué pregunta nos hacemos. Hay tres posibilidades.
3.5.1 Efecto sobre la variable latente: \(E(y^* \mid \mathbf{x})\)
Es el efecto sobre el «deseo» subyacente. Idéntico a MCO, pero se refiere a una variable que no siempre observamos. Útil cuando la pregunta es sobre el proceso latente: «¿cómo afecta la educación al deseo de trabajar?»
3.5.2 Efecto sobre los no censurados: \(E(y \mid \mathbf{x}, y > 0)\)
El factor \(\Phi(\mathbf{x}\boldsymbol{\beta}/\sigma)\) es la probabilidad de no estar censurado. Si casi todos están censurados (\(\Phi \approx 0\)), el efecto es casi nulo. Si casi nadie lo está (\(\Phi \approx 1\)), el efecto es prácticamente \(\beta_j\). Es el efecto más usado en la práctica: combina el margen extensivo (pasar de censurado a no censurado) con el intensivo (cambio en la cantidad).
Resumen de las tres medias condicionales del modelo Tobit
Media
Nombre
Efecto marginal
Pregunta que responde
Ejemplo
\(E(y^* \mid \mathbf{x})\)
Variable latente
\(\beta_j\)
¿Cómo cambia el deseo latente?
Efecto de educación sobre deseo de trabajar
\(E(y \mid \mathbf{x},\, y > 0)\)
No censuradas (truncada)
\(\beta_j \times [1 - \lambda(z + \lambda)]\)
Dado que ya trabaja, ¿cuánto más?
Si ya trabaja, ¿cuántas horas más por año de educación?
Efecto total sobre horas trabajadas (incluye los que no trabajan)
La relación entre las tres: Siempre se cumple que el efecto sobre \(E(y^*)\) > efecto sobre \(E(y \mid y > 0)\) > efecto sobre \(E(y)\). En la práctica, reporta siempre los AME (efectos marginales promedio) sobre \(E(y)\).
3.6 Contrastes de especificación
El modelo Tobit descansa en dos supuestos sobre el término de error que deben verificarse empíricamente:
1. Normalidad. El supuesto \(u_i \sim N(0,\sigma^2)\) es más fuerte que en MCO: en MCO la normalidad es solo necesaria para la inferencia en muestras finitas, pero en el Tobit es necesaria para la consistencia del estimador. Si los errores no son normales, el Tobit MLE es inconsistente incluso en muestras grandes. El test estándar es el de Jarque-Bera sobre los residuos.
2. Homocedasticidad. Si \(\sigma^2\) depende de \(\mathbf{x}_i\), el estimador también es inconsistente. Esto lo diferencia de MCO, donde la heterocedasticidad solo afecta a la eficiencia. El test de Breusch-Pagan aplicado a los residuos ordinarios da una señal informal útil.
Table 3.3: Contrastes de especificación del modelo Tobit. Los residuos se calculan como y - E[y|x] donde E[y|x] usa la fórmula de McDonald-Moffitt. Un p-valor alto en el test de Jarque-Bera indica que no se rechaza la normalidad; un p-valor bajo en Breusch-Pagan sugiere heterocedasticidad.
Los tres casos prácticos de este capítulo aplican el análisis Tobit a contextos económicos distintos: donaciones benéficas (elevada fracción de no donantes), gasto en formación profesional (personas que no invierten en formación), y el mismo dataset ilustrativo de seguros (CP01). En cada caso el alumno debe identificar la fracción de censura, comparar MCO y Tobit, calcular los efectos marginales de McDonald-Moffitt y verificar los supuestos.
3.7.1 Caso práctico 1: Gasto en seguros médicos
El Caso Práctico 1 coincide con el modelo ilustrativo desarrollado en las secciones anteriores, que el alumno puede reproducir íntegramente con el siguiente script:
T03_CP01_mECO_Tobit_Seguros.R
3.7.2 Caso práctico 2: Donaciones benéficas
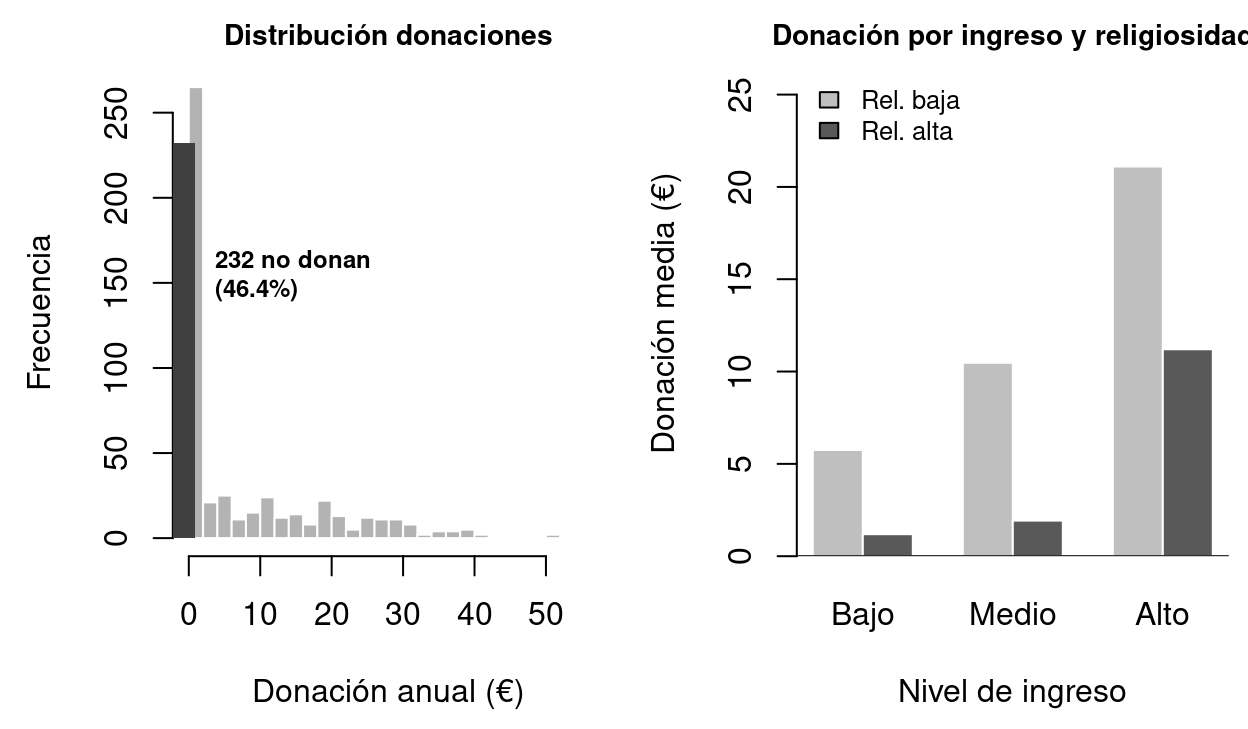
Contexto. El dataset CP02 recoge 500 observaciones sobre donaciones anuales a organizaciones benéficas (en €). El 46.4% de los encuestados declara no haber realizado ninguna donación en el último año. Entre los que sí donaron, el importe medio fue de 15.3€. Las covariables son: ingreso anual bruto, edad, índice de religiosidad (0-5), educación, indicador de tener hijos y sexo.
Code
par(mfrow=c(1,2), mar=c(4.5,4.5,1.8,0.5), cex.main=0.88)n_cd <-sum(donaciones$donacion==0)hist(donaciones$donacion, breaks=30, col=gray(0.70), border="white",main="Distribución donaciones",xlab="Donación anual (€)", ylab="Frecuencia")rect(par("usr")[1], 0, 0.8, n_cd, col=gray(0.25), border=NA)text(1, n_cd*0.65,sprintf("%d no donan\n(%.1f%%)", n_cd, 100*n_cd/nrow(donaciones)),pos=4, cex=0.75, font=2)# Donación media por ingreso y religiosidad (agrupado)donaciones$ing_g <-cut(donaciones$ingreso, breaks=c(14,30,50,150),labels=c("Bajo","Medio","Alto"))donaciones$relig_g <-ifelse(donaciones$religiosidad>=3,"Alta","Baja")med_don <-tapply(donaciones$donacion, list(donaciones$ing_g, donaciones$relig_g), mean)bp_d <-barplot(t(med_don), beside=TRUE,col=gray(c(0.75,0.35)), border="white",ylim=c(0,max(med_don)*1.25),names.arg=c("Bajo","Medio","Alto"),xlab="Nivel de ingreso", ylab="Donación media (€)",main="Donación por ingreso y religiosidad",legend.text=c("Rel. baja","Rel. alta"),args.legend=list(bty="n", cex=0.8, x="topleft"))abline(h=0)par(mfrow=c(1,1))
Figure 3.4: Gasto en donaciones benéficas (CP02). Panel izquierdo: la distribución muestra la masa discreta en 0 (46.4%) y la distribución continua de los valores positivos. Panel derecho: los donantes tienen mayor nivel de religiosidad que los no donantes en todos los grupos de ingreso, lo que confirma que la religiosidad es el predictor más importante.
La religiosidad emerge como el predictor más potente: cada punto adicional en el índice (0-5) aumenta la donación esperada en 2.26€/año (AME). El efecto del ingreso es positivo pero moderado: cada €1.000 adicionales de ingreso aumenta la donación esperada en 0.16€/año. El alumno puede reproducir este análisis con el siguiente script:
T03_CP02_mECO_Tobit_Donaciones.R
3.7.3 Caso práctico 3: Gasto mensual en formación profesional
Contexto. El dataset CP03 recoge la inversión mensual en formación profesional (cursos, certificaciones, libros técnicos) de 600 trabajadores. El 39.3% no invierte nada en formación. Entre quienes sí invierten, el gasto medio es de 42.6€/mes. Las covariables son: ingreso mensual, edad, educación, trabajar en sector privado, haber estado desempleado previamente, sexo y antigüedad laboral.
Table 3.5: Modelo Tobit para gasto en formación profesional (CP03). Trabajar en el sector privado y haber estado desempleado previamente son los predictores con mayor efecto, lo que refleja la mayor presión competitiva y la motivación de reinserción.
Los trabajadores del sector privado invierten 29.61€/mes más en formación que los del sector público (AME), lo que refleja la mayor presión competitiva del mercado privado. Haber pasado previamente por el desempleo también aumenta la inversión en formación, posiblemente como estrategia preventiva ante nuevos episodios de desempleo. El alumno puede reproducir y extender este análisis con el siguiente script:
T03_CP03_mECO_Tobit_Formacion.R
3.8 Guía de comandos R para este capítulo
3.8.1 tobit() — Estimación del modelo Tobit (paquete AER)
El modelo Tobit se estima con la función tobit() del paquete AER. A diferencia de lm() o glm(), tobit() utiliza MLE para estimar simultáneamente los coeficientes \(\boldsymbol{\beta}\) y el parámetro de escala \(\sigma\), teniendo en cuenta de forma correcta tanto las observaciones censuradas como las no censuradas.
Los parámetros esenciales son: la fórmula y ~ x1 + x2 + ... especifica la variable dependiente y las covariables; left = 0 indica el punto de censura por la izquierda (el más habitual, cuando la variable no puede ser negativa); right = valor se usaría para censura por la derecha; data es el dataframe. Los coeficientes estimados se extraen con coef(tob) y el parámetro sigma con tob$scale.
3.8.2 predict(tob, type = “lp”) — Predictor lineal del Tobit
Para calcular los efectos marginales del Tobit es necesario obtener el predictor lineal \(\mathbf{x}_i'\hat{\boldsymbol{\beta}}\) para cada observación. La función predict() con el argumento type = "lp" devuelve directamente ese vector, evitando el cálculo manual mediante multiplicación matricial.
xb <-predict(tob, newdata = seguros, type ="lp")z <- xb / tob$scale # índice normalizado z = x'β / σPhi <-pnorm(z) # probabilidad de no estar censurado
type = "lp" (linear predictor) devuelve el índice lineal sin aplicar ninguna transformación. newdata puede ser el dataset original o un nuevo dataframe para predicciones fuera de la muestra. El cociente xb / tob$scale produce el argumento normalizado \(z\) que entra en la función \(\Phi\) para calcular efectos marginales.
El efecto marginal del Tobit sobre el valor esperado observado \(E[y|\mathbf{x}]\) no es simplemente \(\beta_j\), sino \(\beta_j\) multiplicado por la probabilidad de estar por encima del umbral de censura. Este es el resultado fundamental de McDonald y Moffitt (1980).
# Elementos necesariosbeta <-coef(tob)sig <- tob$scalexb <-predict(tob, newdata = datos, type ="lp")Phi <-pnorm(xb / sig)imr <-dnorm(xb / sig) / Phi # inverse Mills ratio# AME sobre E[y|x]: efecto sobre el gasto esperado totalame_obs <-mean(Phi) * beta["renta"]# AME sobre E[y|y>0]: efecto sobre el gasto esperado dado que es positivoame_cond <-mean(1- (xb/sig)*imr - imr^2) * beta["renta"]
pnorm(xb/sig) es la probabilidad de que la observación no esté censurada (\(\Phi(z)\)). dnorm(xb/sig)/Phi es el inverse Mills ratio (IMR), que aparece en la esperanza condicional truncada. El AME observado multiplica \(\Phi\) promedio por \(\beta_j\); el AME condicional aplica la corrección adicional por la no linealidad de la esperanza truncada.
3.8.4 jb_test y bp_test — Contrastes de especificación sobre los residuos
El modelo Tobit exige normalidad y homocedasticidad del término de error para ser consistente. Los residuos del Tobit se definen como \(e_i = y_i - E[y_i|\mathbf{x}_i]\), donde \(E[y_i|\mathbf{x}_i]\) usa la fórmula de McDonald-Moffitt. Sobre estos residuos se aplican el test de Jarque-Bera (normalidad) y el de Breusch-Pagan (homocedasticidad).
# Residuos del Tobite_hat <- datos$y -as.numeric(Phi) * (as.numeric(xb) + sig *as.numeric(imr))# Test de Jarque-Bera (normalidad)s <-mean(((e_hat -mean(e_hat))/sd(e_hat))^3) # asimetríak <-mean(((e_hat -mean(e_hat))/sd(e_hat))^4) # curtosisJB <-length(e_hat)/6* (s^2+ (k -3)^2/4)p_JB <-1-pchisq(JB, df =2)# Test de Breusch-Pagan informal (homocedasticidad)aux <-lm(e_hat^2~ x1 + x2 + x3, data = datos)BP <-summary(aux)$r.squared *length(e_hat)p_BP <-1-pchisq(BP, df =3)
El estadístico Jarque-Bera (\(JB\)) combina la asimetría \(s\) y la curtosis \(k\) en un único test \(\chi^2_2\). Un \(p\)-valor pequeño rechaza la normalidad. El test de Breusch-Pagan regresa los cuadrados de los residuos sobre las covariables: un \(R^2\) elevado indica que la varianza no es constante (heterocedasticidad).
Los scripts de este capítulo están disponibles en la carpeta scripts/ del repositorio del manual, en:
Cada script realiza el ciclo completo: EDA, estimación MCO y Tobit, comparación de coeficientes, efectos marginales de McDonald-Moffitt y contrastes de especificación.
McDonald, John F., and Robert A. Moffitt. 1980. “The Uses of Tobit Analysis.”The Review of Economics and Statistics 62 (2): 318–21.
Tobin, James. 1958. “Estimation of Relationships for Limited Dependent Variables.”Econometrica 26 (1): 24–36.