library(kableExtra); library(MASS); library(AER)
load("data/T01_CP03_visitas_medico.RData")
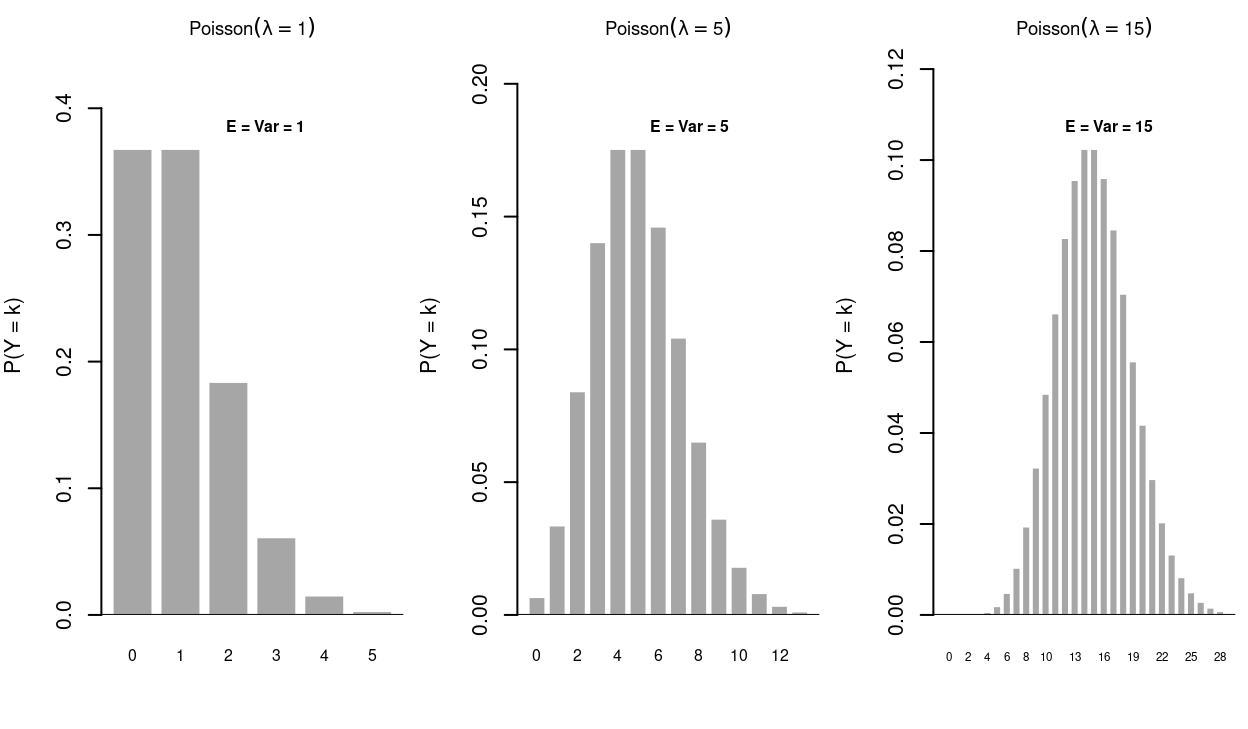
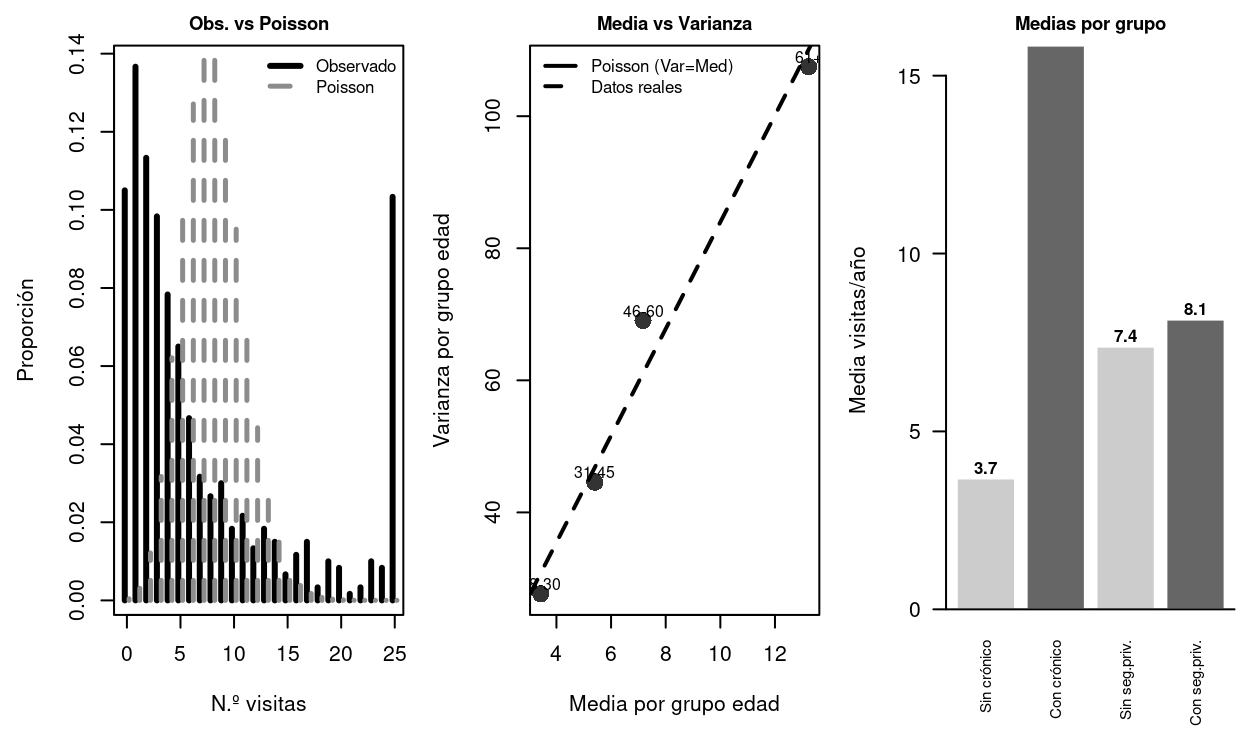
par(mfrow=c(1,3), mar=c(4.5,4.5,1.8,0.5), cex.main=0.88)
# Panel 1: observado vs Poisson
mu_v <- mean(medico$visitas)
k_lim <- min(max(medico$visitas), 25)
obs_f <- table(factor(pmin(medico$visitas,25), levels=0:25))/nrow(medico)
plot(0:25-0.2, as.numeric(obs_f), type="h", lwd=3, lty=1,
xlab="N.º visitas", ylab="Proporción", main="Obs. vs Poisson")
lines(0:25+0.2, dpois(0:25, mu_v), type="h", lwd=2.5, lty=2, col=gray(0.55))
legend("topright", legend=c("Observado","Poisson"),
lty=c(1,2), lwd=c(3,2.5), col=c("black",gray(0.55)), bty="n", cex=0.8)
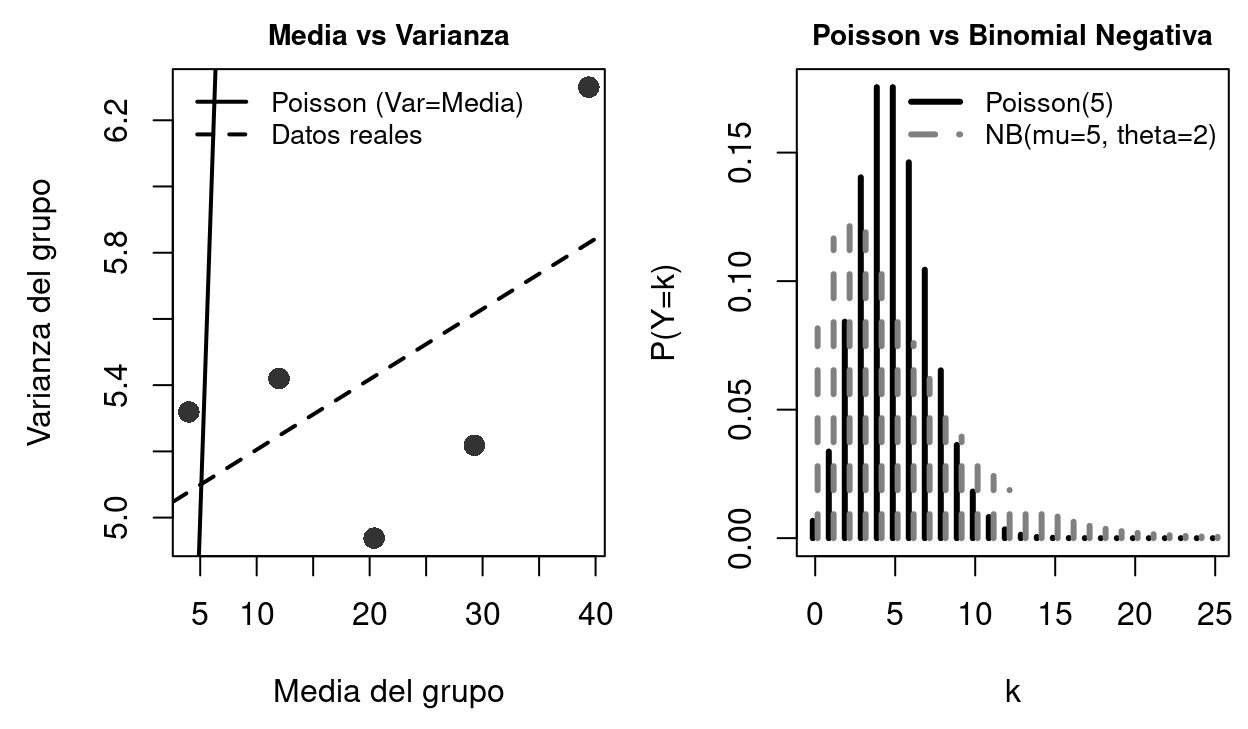
# Panel 2: media vs varianza por grupos de edad
medico$edad_g <- cut(medico$edad, breaks=c(17,30,45,60,80), labels=c("18-30","31-45","46-60","61+"))
m_g <- tapply(medico$visitas, medico$edad_g, mean)
v_g <- tapply(medico$visitas, medico$edad_g, var)
plot(m_g, v_g, pch=16, cex=1.8, col=gray(0.2),
xlab="Media por grupo edad", ylab="Varianza por grupo edad",
main="Media vs Varianza")
abline(0,1, lwd=2, lty=1)
abline(lm(v_g~m_g), lwd=2, lty=2)
text(m_g, v_g+1.5, names(m_g), cex=0.75)
legend("topleft", legend=c("Poisson (Var=Med)","Datos reales"),
lty=c(1,2), lwd=2, bty="n", cex=0.8)
# Panel 3: medias por grupos
grupos_v <- c("Sin crónico","Con crónico","Sin seg.priv.","Con seg.priv.")
medias_v <- c(mean(medico$visitas[medico$cronico==0]),
mean(medico$visitas[medico$cronico==1]),
mean(medico$visitas[medico$seguro_privado==0]),
mean(medico$visitas[medico$seguro_privado==1]))
bp_v <- barplot(medias_v, col=gray(c(0.80,0.40,0.80,0.40)), border="white",
names.arg=grupos_v, cex.names=0.72,
ylab="Media visitas/año", main="Medias por grupo", las=2)
abline(h=0)
text(bp_v, medias_v+0.3, sprintf("%.1f",medias_v), cex=0.8, font=2)
par(mfrow=c(1,1))