En muchos problemas económicos, la variable de interés no es qué ocurre sino cuándo ocurre. ¿Cuántos meses tarda un desempleado en encontrar trabajo? ¿Cuántos años sobrevive una empresa desde su fundación? ¿Cuánto tiempo transcurre hasta que un deudor impaga su crédito? ¿Cuántos meses pasan entre dos compras de un bien duradero? Estas son preguntas sobre duración: el tiempo que transcurre desde que se inicia un estado o evento hasta que termina.
Los datos de duración presentan dos particularidades que hacen inapropiada la regresión lineal ordinaria. La primera es la no negatividad: la duración es siempre positiva, y su distribución suele ser fuertemente asimétrica hacia la derecha — muchas duraciones cortas y pocas muy largas. La regresión lineal podría predecir duraciones negativas, lo cual carece de sentido.
La segunda particularidad — y la más importante — es la censura. Para algunos individuos de la muestra, el evento de interés no se ha producido cuando finaliza el período de observación. Un desempleado que sigue sin trabajo cuando termina el estudio tiene una duración del desempleo incompleta: sabemos que lleva al menos 18 meses, pero no sabemos cuánto durará en total. Un crédito que no ha impagado al cierre del análisis puede impagar mañana o nunca. Si descartamos estas observaciones censuradas o les asignamos una duración arbitraria, introducimos un sesgo sistemático: estaríamos infravalorando la duración media porque excluimos precisamente a los que más duran. Los modelos de duración (también llamados modelos de supervivencia en bioestadística, o modelos de riesgos en ciencias actuariales) están diseñados específicamente para incorporar la información parcial que proporcionan las observaciones censuradas.
En economía, las aplicaciones son amplísimas. En economía laboral, el análisis de la duración del desempleo y de los efectos de las prestaciones sobre la búsqueda de empleo. En finanzas, la modelización del tiempo hasta el impago de un crédito (credit scoring). En economía industrial, la supervivencia de empresas y la duración de patentes. En economía de la salud, el tiempo hasta la readmisión hospitalaria. En marketing, el tiempo entre compras repetidas.
7.2 Conceptos fundamentales
7.2.1 La función de supervivencia
Sea \(T\) una variable aleatoria continua y no negativa que mide el tiempo hasta el evento. Su función de distribución acumulada es \(F(t) = P(T \leq t)\) y su función de densidad es \(f(t) = F'(t)\). La función de supervivencia mide la probabilidad de que el evento no haya ocurrido antes del tiempo \(t\):
\[S(t) = P(T > t) = 1 - F(t) \tag{7.1}\]
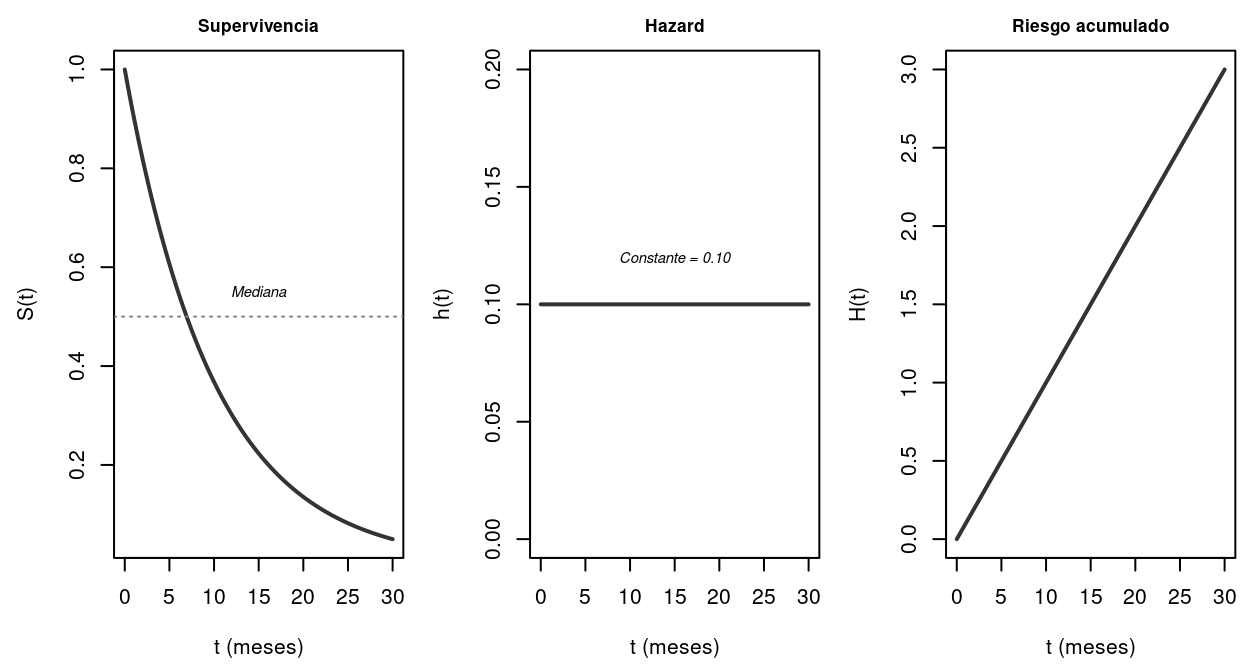
\(S(t)\) es monótonamente decreciente, con \(S(0) = 1\) (al inicio todos “sobreviven”) y \(\lim_{t\to\infty} S(t) = 0\) (eventualmente todos experimentan el evento). La función de supervivencia contiene toda la información sobre la distribución de la duración: conocer \(S(t)\) equivale a conocer \(F(t)\).
7.2.2 La función de riesgo (hazard)
La función de riesgo o tasa de fallo instantánea es quizá el concepto más importante del análisis de duración. Mide la probabilidad instantánea de que el evento ocurra en un momento dado, condicionada a haber sobrevivido hasta ese momento:
\[h(t) = \lim_{\Delta t \to 0} \frac{P(t \leq T < t + \Delta t \mid T \geq t)}{\Delta t} = \frac{f(t)}{S(t)} = -\frac{d}{dt}\ln S(t) \tag{7.2}\]
El hazard no es una probabilidad — puede ser mayor que 1, porque es una tasa (eventos por unidad de tiempo). Su interpretación es intuitiva: si \(h(t) = 0.05\) en un modelo mensual de desempleo, significa que un desempleado que ha sobrevivido hasta el mes \(t\) tiene una probabilidad del 5% de encontrar empleo en el próximo mes.
La forma del hazard tiene interpretación económica directa. Un hazard creciente (dependencia positiva de la duración) indica que cuanto más tiempo llevas en el estado, más probable es salir. Ejemplo: la probabilidad de encontrar empleo puede aumentar con el tiempo si el desempleado mejora sus habilidades de búsqueda. Un hazard decreciente (dependencia negativa) indica lo contrario: cuanto más tiempo llevas, más difícil es salir. Ejemplo: el estigma del desempleo de larga duración reduce las probabilidades de contratación. Un hazard constante implica que la duración pasada es irrelevante (propiedad de falta de memoria).
7.2.3 El riesgo acumulado
El riesgo acumulado integra el hazard desde el inicio hasta \(t\):
De esta relación fundamental se obtiene \(S(t) = \exp(-H(t))\), que conecta las tres funciones. Conocer cualquiera de las tres — \(S(t)\), \(h(t)\) o \(H(t)\) — permite derivar las otras dos.
Figure 7.1: Las tres funciones fundamentales para una distribución exponencial (hazard constante, lambda=0.1). S(t) decrece exponencialmente; h(t) es constante; H(t) crece linealmente.
7.2.4 Ejemplo numérico: cálculo de S(t) y h(t)
Supongamos que la duración del desempleo sigue una distribución exponencial con \(\lambda = 0.1\) (por mes). Calculemos algunas magnitudes concretas para fijar la intuición:
La probabilidad de seguir desempleado tras 6 meses es \(S(6) = e^{-0.1 \times 6} = e^{-0.6} = 0.549\), es decir, el 54.9% de los desempleados siguen sin empleo a los 6 meses. La mediana de la distribución — el tiempo en el que el 50% ha encontrado empleo — es \(t_{0.5} = -\ln(0.5)/\lambda = 0.693/0.1 = 6.93\) meses. La duración esperada es \(E[T] = 1/\lambda = 10\) meses.
7.3 Tipos de censura
La censura por la derecha es la más común en datos económicos: el evento no se ha producido al final del estudio. Solo sabemos que \(T > c\), donde \(c\) es el tiempo de censura. Hay dos subtipos. La censura de Tipo I ocurre cuando el estudio tiene una fecha de finalización fija — todas las observaciones que no hayan experimentado el evento en esa fecha están censuradas. La censura de Tipo II ocurre cuando se fija de antemano un número de eventos a observar.
La censura por la izquierda ocurre cuando el evento ya se había producido antes del inicio de la observación. Por ejemplo, si estudiamos la duración del desempleo entrevistando a trabajadores y algunos ya habían estado desempleados antes de que comenzara el estudio. La censura por intervalo se da cuando solo sabemos que el evento ocurrió entre dos momentos de inspección — por ejemplo, un crédito que estaba al corriente en enero pero había impagado para marzo.
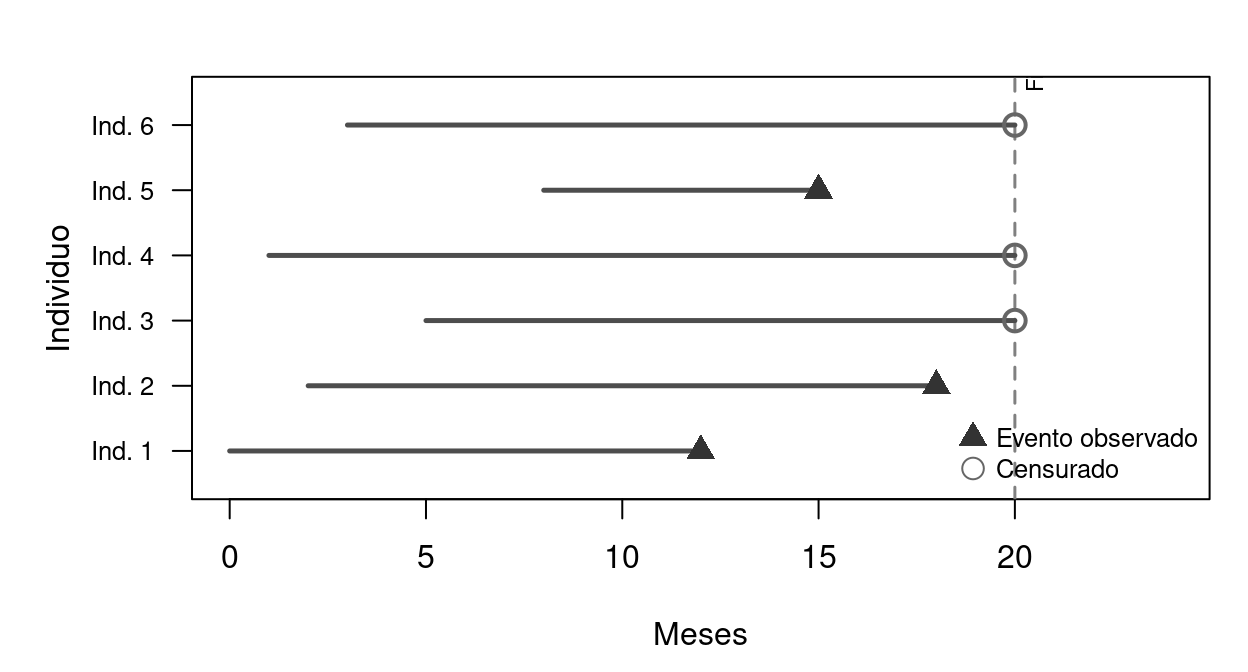
Figure 7.2: Representación de observaciones censuradas y no censuradas. Las flechas horizontales muestran la duración de cada individuo. El triángulo marca el evento; el círculo marca la censura (fin del estudio sin evento).
En el gráfico, los individuos 1, 2 y 5 experimentan el evento antes del fin del estudio. Los individuos 3, 4 y 6 están censurados: seguían en el estado cuando terminó el estudio. Para estos últimos, sabemos que su duración es al menos la observada, pero no sabemos la duración total. La censura es información parcial, no ausencia de información, y los modelos de duración la aprovechan.
7.4 Estimación no paramétrica: Kaplan-Meier
7.4.1 El estimador
El estimador de Kaplan-Meier(1958) estima la función de supervivencia \(S(t)\) sin asumir ninguna distribución paramétrica. La idea es simple pero potente: en cada momento en que ocurre un evento, actualizar la probabilidad de supervivencia.
Sean \(t_1 < t_2 < \cdots < t_D\) los tiempos distintos en los que ocurren eventos. En cada \(t_j\), sean \(d_j\) el número de eventos y \(n_j\) el número de individuos en riesgo (que no han experimentado el evento ni han sido censurados antes de \(t_j\)). El estimador KM es:
La curva KM es una función escalonada que desciende en cada tiempo de evento. Las observaciones censuradas no producen escalones: salen del conjunto en riesgo \(n_j\) pero no contribuyen eventos \(d_j\).
7.4.2 Ejemplo numérico paso a paso
Calculemos KM con 10 observaciones de duración del desempleo (en meses): 3, 5+, 7, 8, 8, 10+, 12, 14+, 18, 24, donde el signo + indica censura.
Table 7.1: Cálculo paso a paso de Kaplan-Meier. En cada tiempo de evento se actualiza la probabilidad de supervivencia multiplicando por la fracción de supervivientes.
Tiempo
Eventos
En riesgo
Nota
1 - d/n
S(t)
3
1
10
0.9000
0.9000
7
1
8
1 censurado en t=5
0.8750
0.7875
8
2
7
0.7143
0.5625
12
1
4
1 censurado en t=10
0.7500
0.4219
18
1
3
1 censurado en t=14
0.6667
0.2813
24
1
2
0.5000
0.1406
La supervivencia estimada a los 8 meses es \(\hat{S}(8) = 0.9 \times 0.875 \times 0.571 = 0.450\). Esto significa que el 45% de los desempleados siguen sin empleo a los 8 meses.
7.4.3 Test de log-rank
Para comparar las curvas de supervivencia de dos o más grupos (por ejemplo, hombres vs mujeres, o con prestación vs sin prestación), el test de log-rank contrasta \(H_0:\) las funciones de supervivencia son iguales en todos los grupos. Es el análogo no paramétrico del test chi-cuadrado para datos de duración. En R: survdiff(Surv(tiempo, evento) ~ grupo).
7.5 Modelos paramétricos
7.5.1 El modelo exponencial
El modelo más simple asume un hazard constante: \(h(t) = \lambda\) para todo \(t > 0\). Esto implica:
La propiedad fundamental del exponencial es la falta de memoria: \(P(T > t + s \mid T > t) = P(T > s)\). Es decir, la probabilidad de sobrevivir \(s\) unidades más es independiente del tiempo ya transcurrido. Económicamente, esto equivale a decir que un desempleado que lleva 12 meses tiene las mismas probabilidades de encontrar empleo el próximo mes que uno que acaba de quedarse desempleado. Este supuesto es a menudo poco realista, pero el modelo exponencial es útil como punto de partida y como caso particular de distribuciones más flexibles.
Con covariables, se parametriza \(\lambda_i = \exp(\mathbf{x}_i'\boldsymbol{\beta})\), lo que garantiza \(\lambda_i > 0\).
7.5.2 El modelo Weibull
La distribución Weibull generaliza el exponencial añadiendo un parámetro de forma \(\alpha > 0\) que permite que el hazard cambie con el tiempo:
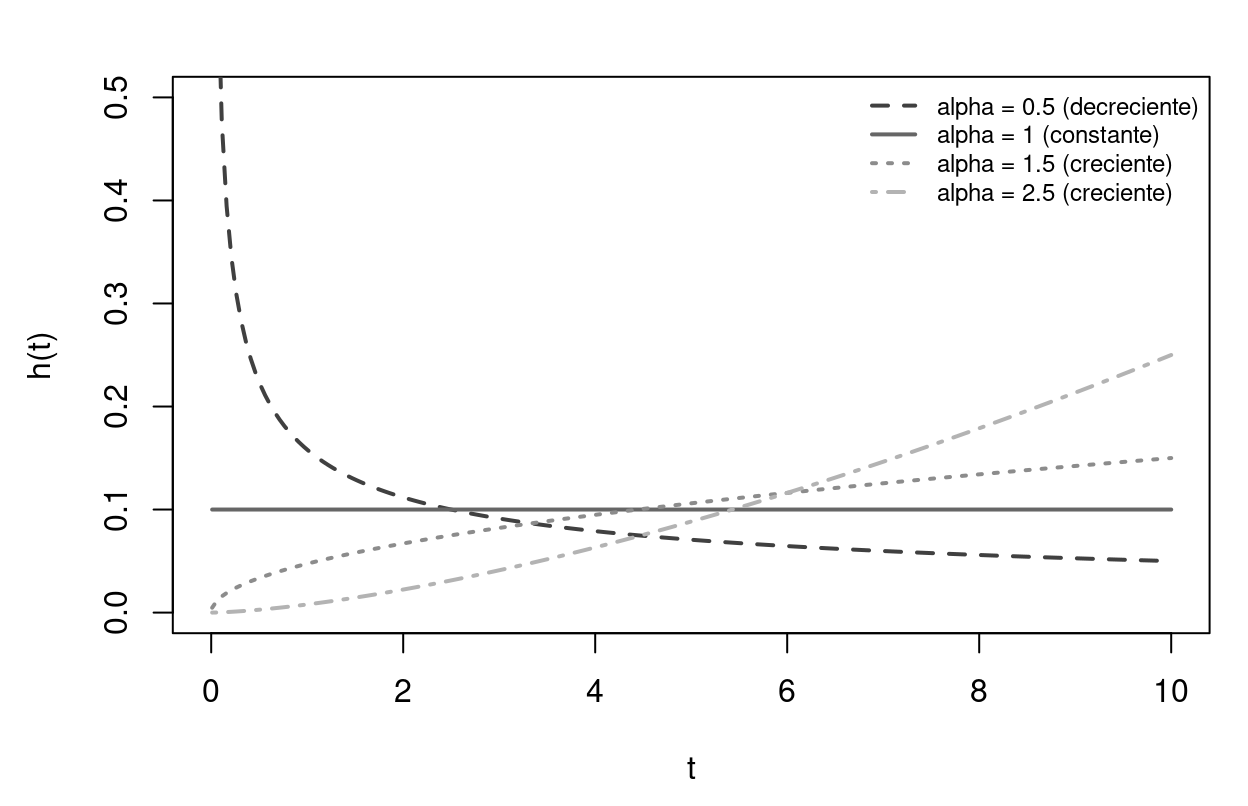
El parámetro \(\alpha\) tiene interpretación directa. Si \(\alpha = 1\), se recupera el exponencial (hazard constante). Si \(\alpha > 1\), el hazard es creciente: la probabilidad de salir del estado aumenta con el tiempo (dependencia positiva). Si \(\alpha < 1\), el hazard es decreciente: cuanto más tiempo llevas, más difícil es salir (dependencia negativa).
Figure 7.3: Función de riesgo Weibull para distintos valores del parámetro de forma alpha. Con alpha=1.5 o 2.5, el riesgo crece (mortalidad por envejecimiento, desgaste de máquinas). Con alpha=0.5, decrece (mortalidad infantil, fallos tempranos).
7.5.3 Otros modelos paramétricos
La distribución log-normal asume que \(\ln T \sim N(\mu, \sigma^2)\). Su hazard tiene forma de campana invertida: crece inicialmente, alcanza un máximo y luego decrece. Es apropiada cuando el riesgo primero aumenta y después disminuye (por ejemplo, el riesgo de divorcio, que crece en los primeros años de matrimonio y luego decrece).
La distribución log-logística tiene un hazard similar al log-normal pero con colas más pesadas. Es popular en economía porque admite una forma cerrada para \(S(t)\).
7.5.4 Verosimilitud con datos censurados
La contribución a la verosimilitud difiere según la observación esté censurada o no. Si el individuo \(i\) experimenta el evento en \(t_i\), contribuye con su densidad \(f(t_i)\). Si está censurado en \(c_i\), solo sabemos que \(T_i > c_i\), y contribuye con la probabilidad de supervivencia \(S(c_i)\). Con el indicador \(\delta_i = 1\) si hay evento y \(\delta_i = 0\) si hay censura:
Las observaciones censuradas contribuyen solo con \(\ln S(t_i) = -H(t_i)\): aportan información (el individuo sobrevivió al menos hasta \(t_i\)) pero no información sobre el momento exacto del evento.
7.6 El modelo de Cox
7.6.1 Riesgos proporcionales
El modelo de Cox(1972) es semiparamétrico: especifica cómo las covariables afectan al riesgo, pero deja completamente libre la forma del riesgo base. Esta flexibilidad es su mayor fortaleza.
donde \(h_0(t)\) es el riesgo base (la función de riesgo de un individuo con todas las covariables iguales a cero) y \(\exp(\mathbf{x}'\boldsymbol{\beta})\) es el multiplicador que depende de las covariables. El supuesto clave es que este multiplicador es constante en el tiempo: las covariables desplazan el hazard hacia arriba o hacia abajo de forma proporcional, pero no cambian su forma.
7.6.2 Interpretación: los Hazard Ratios
La interpretación de los coeficientes del modelo de Cox se realiza mediante los hazard ratios (HR):
Un \(\text{HR} > 1\) indica que la covariable aumenta el riesgo instantáneo de experimentar el evento — es decir, acorta la duración esperada. Un \(\text{HR} < 1\) indica que la covariable reduce el riesgo — alarga la duración. Un \(\text{HR} = 1\) indica ausencia de efecto.
Por ejemplo, si en un modelo de duración del desempleo el HR de “posee título universitario” es 1.35, significa que los universitarios tienen un riesgo de encontrar empleo un 35% mayor en cada instante — encuentran empleo más rápido.
7.6.3 La verosimilitud parcial de Cox
La idea brillante de Cox fue proponer un método de estimación que no requiere especificar \(h_0(t)\). La verosimilitud parcial solo usa la información sobre el orden de los eventos, no los tiempos exactos:
donde \(\mathbf{x}_{(j)}\) son las covariables del individuo que experimenta el evento en \(t_j\), y \(R(t_j)\) es el conjunto en riesgo en ese momento. Cada factor es la probabilidad de que, entre todos los individuos en riesgo en \(t_j\), sea precisamente el individuo \((j)\) quien experimenta el evento.
7.6.4 Diagnósticos: test de proporcionalidad
El supuesto de riesgos proporcionales implica que el HR no cambia con el tiempo. Los residuos de Schoenfeld permiten verificar este supuesto: si los residuos muestran una tendencia temporal, la proporcionalidad se viola para esa covariable. El test formal de cox.zph() en R contrasta la hipótesis nula de proporcionalidad. Si se rechaza, las alternativas incluyen estratificar por la variable problemática o incluir una interacción con el tiempo.
Los residuos de Cox-Snell se usan para evaluar el ajuste global del modelo. Si el modelo es correcto, los residuos de Cox-Snell deben seguir una distribución exponencial con parámetro 1.
7.7 Ejemplo práctico: duración del desempleo
Analizamos datos simulados de 800 individuos con información sobre la duración del desempleo (en meses). Las covariables son edad, años de educación, si percibe prestación por desempleo y sexo. Los datos están generados con una distribución Weibull con \(\alpha = 1.3\) (hazard creciente: la probabilidad de encontrar empleo aumenta con el tiempo de búsqueda). Aproximadamente un 30% de las observaciones están censuradas.
Antes de estimar ningún modelo, examinemos los datos gráficamente. El gráfico de Kaplan-Meier por grupo de prestación nos permite ver si los que cobran prestación tardan más en encontrar empleo, sin imponer ninguna forma funcional:
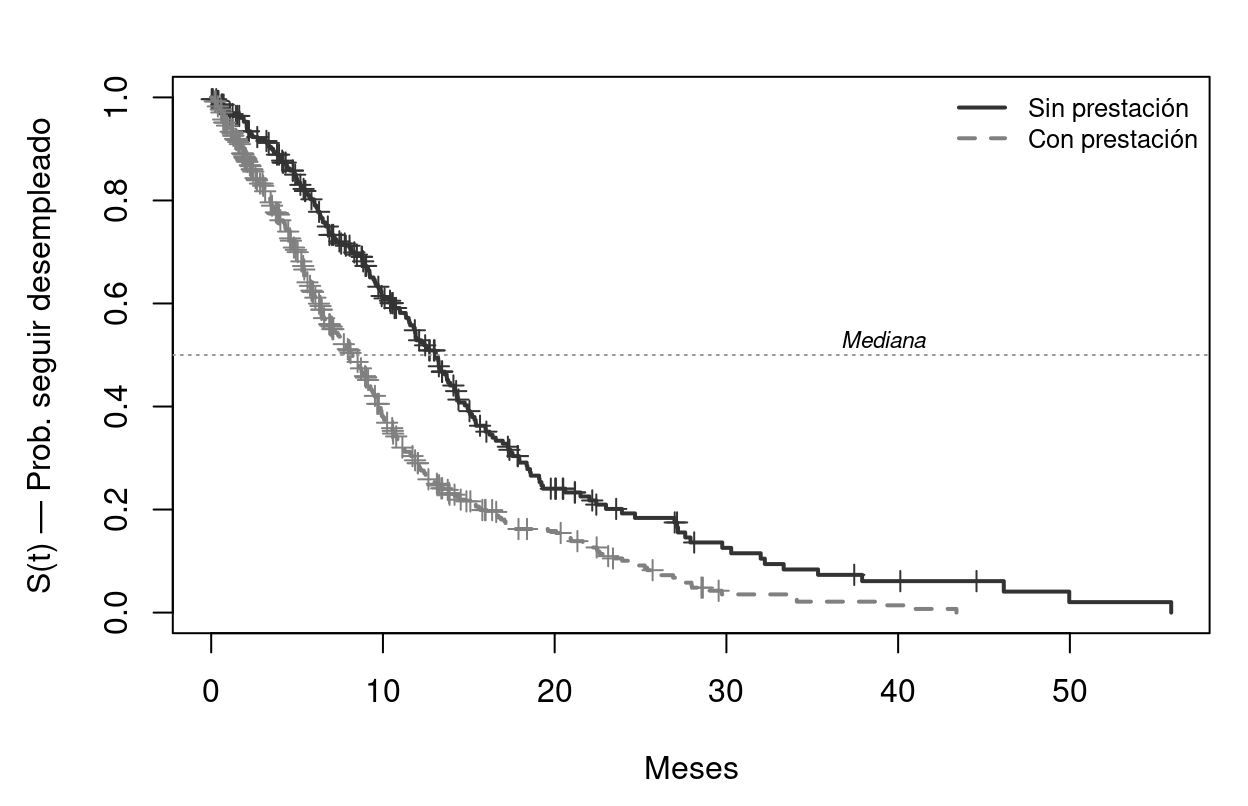
Figure 7.4: Curvas de Kaplan-Meier por percepción de prestación. Los que cobran prestación (línea discontinua) tienen menor probabilidad de encontrar empleo a cualquier horizonte temporal. Las marcas verticales indican censuras.
La separación entre las dos curvas confirma que la prestación alarga la duración del desempleo — un resultado clásico en economía laboral que refleja el efecto desincentivador de la prestación sobre la intensidad de búsqueda.
7.7.1 Estimación del modelo de Cox
Table 7.2: Modelo de Cox para la duración del desempleo. Un HR>1 indica que la covariable aumenta el riesgo de salir del desempleo (acorta la duración); HR<1 la reduce (alarga la duración).
Variable
HR
Coef.
EE
p-valor
Edad
1.0252
0.0249
0.0057
0.0000
Educación
0.8925
-0.1137
0.0159
0.0000
Prestación
1.9206
0.6526
0.0918
0.0000
Sexo (mujer)
1.2820
0.2484
0.0852
0.0035
La educación tiene HR 0.893: cada año adicional de educación reduce el riesgo de salir del desempleo, es decir, los más educados tardan paradójicamente más en encontrar empleo (posiblemente porque buscan empleos más cualificados y específicos).
La prestación tiene HR 1.921, confirmando que recibir prestación aumenta el riesgo de encontrar empleo más rápido. La concordancia del modelo es 0.626.
7.7.2 Verificación de proporcionalidad
El test de Schoenfeld arroja un p-valor global de 0.0581. No se rechaza la hipótesis de proporcionalidad: el modelo de Cox es adecuado.
7.7.3 Comparación con modelo Weibull
El modelo paramétrico Weibull estima un parámetro de forma \(\hat{\alpha} =\) 1.333. Como alpha > 1, el hazard es creciente: la probabilidad de encontrar empleo aumenta con la duración de la búsqueda (dependencia positiva).
7.8 Casos prácticos
7.8.1 Caso Práctico 1: Duración del desempleo
Contexto económico. La duración del desempleo es una variable clave para la política laboral. Se sabe que la percepción de prestaciones por desempleo reduce la intensidad de búsqueda de empleo, alargando la duración del episodio. Cuantificar este efecto es esencial para diseñar prestaciones que protejan al trabajador sin desincentivar excesivamente la búsqueda.
Datos. Muestra de 800 individuos desempleados. La variable dependiente es la duración del desempleo en meses, con aproximadamente un 30% de observaciones censuradas (individuos que seguían desempleados al final del estudio). Las covariables son: edad (años), educación (años de escolarización), prestación (1=percibe prestación por desempleo, 0=no), sexo (1=mujer) y sector previo (Industria, Servicios, Construcción, Agricultura).
Modelo. Se estima un modelo de Cox con edad, educación, prestación y sexo como covariables. Se espera que la educación aumente el hazard (acorte la duración) y que la prestación lo reduzca (alargue la duración). Se verifica la proporcionalidad con el test de Schoenfeld y se compara con un Weibull paramétrico.
Objetivo pedagógico. El alumno aprenderá a estimar curvas de Kaplan-Meier por grupos, interpretar hazard ratios, verificar la proporcionalidad y comparar modelos semiparamétricos con paramétricos.
T07_CP01_mECO_Duracion_Desempleo.R
7.8.2 Caso Práctico 2: Supervivencia de empresas
Contexto económico. La supervivencia empresarial es un indicador fundamental del dinamismo económico. Las empresas con mayor capital inicial, más empleados y que invierten en innovación tienden a sobrevivir más, mientras que un endeudamiento excesivo aumenta el riesgo de cierre. Conocer estos factores permite diseñar políticas de apoyo a emprendedores.
Datos. Muestra de 600 empresas. La variable dependiente es el tiempo de actividad en años, con un 40% de censura (empresas activas al final del estudio). Las covariables son: capital inicial (miles de euros), número de empleados, sector (Tech, Manufactura, Retail, Hostelería), innovación (1=realiza I+D) y ratio de endeudamiento (deuda/activos).
Modelo. Modelo de Cox con las cinco covariables. Se espera que la innovación reduzca el riesgo de cierre (HR < 1) y el endeudamiento lo aumente (HR > 1). El parámetro de forma del Weibull indicará si el riesgo de cierre varía con la edad de la empresa.
Objetivo pedagógico. El alumno aplicará el análisis de supervivencia a un contexto empresarial, interpretará los HR en términos de política económica y comparará Cox con Weibull.
T07_CP02_mECO_Duracion_Empresas.R
7.8.3 Caso Práctico 3: Tiempo hasta impago crediticio
Contexto económico. La modelización del riesgo de impago es la base del credit scoring bancario. Los bancos necesitan estimar la probabilidad de que un crédito impague en función de las características del prestatario y del crédito. Este tipo de modelos determinan la aprobación de créditos y el tipo de interés aplicado.
Datos. Muestra de 1000 créditos. La variable dependiente es el tiempo hasta impago en meses, con un 67% de censura (créditos que no han impagado al cierre). Las covariables son: importe del crédito (euros), tipo de interés (%), ratio deuda/ingreso del prestatario, historial crediticio (1=malo a 5=excelente) y hipoteca (1=tiene hipoteca previa).
Modelo. Modelo de Cox: \(h(t|\mathbf{x}) = h_0(t)\exp(\beta_1 ext{importe} + \beta_2 ext{interés} + \beta_3 ext{ratio\_DI} + \beta_4 ext{historial} + \beta_5 ext{hipoteca})\). Se espera que un mayor ratio deuda/ingreso y un peor historial aumenten el riesgo de impago, y que un buen historial lo reduzca.
Objetivo pedagógico. El alumno comprenderá la aplicación financiera del análisis de duración, trabajará con datos de alta censura (típica en credit scoring) e interpretará los resultados en términos de gestión del riesgo.
T07_CP03_mECO_Duracion_Impago.R
7.9 Lo esencial del capítulo
Los modelos de duración analizan el tiempo hasta un evento, incorporando correctamente la censura mediante la verosimilitud \(L = \prod h(t_i)^{\delta_i} S(t_i)\). Las tres funciones fundamentales — supervivencia \(S(t)\), hazard \(h(t)\) y riesgo acumulado \(H(t)\) — están interrelacionadas: \(S(t) = e^{-H(t)}\).
Kaplan-Meier estima \(S(t)\) sin supuestos distribucionales; el test de log-rank compara curvas entre grupos. Los modelos paramétricos asumen una forma funcional: el exponencial (hazard constante), el Weibull (hazard monótono), el log-normal (hazard no monótono). El modelo de Cox es semiparamétrico — no especifica \(h_0(t)\) pero sí el efecto proporcional de las covariables: \(h(t|\mathbf{x}) = h_0(t)\exp(\mathbf{x}'\beta)\). Los hazard ratios\(\exp(\beta_j)\) miden el cambio proporcional en el riesgo. El test de Schoenfeld verifica el supuesto de proporcionalidad.
7.10 Funciones esenciales de R para duración
Los scripts completos de este capítulo y los casos prácticos están disponibles en el repositorio del manual:
A continuación se describen las funciones de R más relevantes para el análisis abordado en este capítulo.
7.10.1 Surv() — Crear el objeto de supervivencia
La función Surv() del paquete survival crea el objeto especial que combina el tiempo de duración con el indicador de censura. Es el primer paso obligatorio de cualquier análisis de duración.
library(survival)surv_obj <-Surv(tiempo, evento)
El primer argumento es el vector de tiempos de duración. El segundo es el indicador de evento: 1 (o TRUE) si el evento ocurrió, 0 (o FALSE) si la observación está censurada. El objeto resultante se usa como variable dependiente en todas las funciones de supervivencia.
7.10.2 survfit() — Estimación de Kaplan-Meier
La función survfit() estima la curva de supervivencia no paramétrica de Kaplan-Meier. Puede estimarse globalmente o por grupos.
km <-survfit(surv_obj ~1) # KM globalkm_grupo <-survfit(surv_obj ~ grupo) # KM por gruposplot(km_grupo) # gráfico de supervivenciasummary(km) # tabla con S(t), IC, n en riesgo
La fórmula surv_obj ~ 1 estima una única curva para toda la muestra. Si se añade una variable de agrupación (~ grupo), se estiman curvas separadas que pueden compararse visualmente o con el test de log-rank. La función plot() aplicada al resultado genera directamente la curva de supervivencia escalonada característica de KM. summary() produce una tabla detallada con los valores de \(\hat{S}(t)\), intervalos de confianza y el número de individuos en riesgo en cada tiempo.
7.10.3 survdiff() — Test de log-rank
Compara las curvas de supervivencia de dos o más grupos, contrastando la hipótesis nula de que son iguales.
survdiff(surv_obj ~ grupo)
El argumento es la misma fórmula que en survfit(). El resultado incluye el estadístico chi-cuadrado y su p-valor. Si p < 0.05, las curvas difieren significativamente entre grupos.
7.10.4 coxph() — Modelo de riesgos proporcionales de Cox
La función coxph() estima el modelo semiparamétrico de Cox, que modela el efecto de las covariables sobre el riesgo sin especificar la forma del riesgo base.
El summary() del modelo de Cox reporta los coeficientes \(\beta\), los hazard ratios \(\exp(\beta)\) con sus intervalos de confianza al 95%, los errores estándar, los estadísticos z y p-valores, y la concordancia del modelo (análogo del \(R^2\) en regresión: 0.5 = aleatorio, 1 = predicción perfecta). Para extraer solo los hazard ratios: exp(coef(cox)). Para los intervalos de confianza de los HR: exp(confint(cox)).
7.10.5 cox.zph() — Test de proporcionalidad de Schoenfeld
Verifica si el supuesto de riesgos proporcionales se cumple para cada covariable.
zph <-cox.zph(cox)print(zph)plot(zph)
El resultado incluye un p-valor para cada covariable y uno global. Si el p-valor es mayor que 0.05, no se rechaza la proporcionalidad y el modelo de Cox es adecuado. Si se rechaza para alguna variable, se puede estratificar el modelo por esa variable (strata() en la fórmula) o incluir una interacción con el tiempo. La función plot() muestra los residuos de Schoenfeld frente al tiempo — una tendencia visible indica violación de la proporcionalidad.
7.10.6 survreg() — Modelos paramétricos
Estima modelos de duración paramétricos con distintas distribuciones.
survreg(surv_obj ~ x1 + x2, data = datos, dist ="weibull")
El parámetro dist especifica la distribución: "exponential" (hazard constante), "weibull" (hazard monótono), "lognormal" (hazard no monótono, forma de campana) o "loglogistic". Los coeficientes de survreg() se interpretan en la escala del logaritmo del tiempo (modelo AFT — Accelerated Failure Time), no como log-hazard ratios. El parámetro de escala ($scale) se relaciona con la forma del hazard: para Weibull, \(\alpha = 1/\text{scale}\).
Cox, David R. 1972. “Regression Models and Life-Tables.”Journal of the Royal Statistical Society: Series B 34 (2): 187–220.
Kaplan, Edward L., and Paul Meier. 1958. “Nonparametric Estimation from Incomplete Observations.”Journal of the American Statistical Association 53 (282): 457–81.