2.1 El problema económico: cuando el agente dice sí o no
Hay una pregunta que recorre buena parte de la microeconomía aplicada: ¿por qué un agente económico toma una decisión y no otra? ¿Por qué este solicitante recibe el crédito y aquel no? ¿Por qué esta familia contrata un seguro privado y su vecina no? ¿Por qué un estudiante se matricula en la universidad y otro, con notas similares, no lo hace?
Todas estas situaciones comparten una estructura común: la variable que queremos explicar toma exactamente dos valores. Aprueba o no aprueba. Trabaja o no trabaja. Compra o no compra. Es lo que llamamos una decisión binaria, y modelarla correctamente exige herramientas que van más allá del modelo de regresión lineal.
La razón de fondo es estadística, no técnica. Cuando la variable dependiente solo puede ser 0 o 1, lo que realmente queremos modelar es una probabilidad — la probabilidad de que el agente elija la opción 1 dadas sus características —, y las probabilidades tienen propiedades que una recta no puede respetar. Como vimos en el capítulo anterior, el modelo lineal clásico puede predecir probabilidades fuera de \([0,1]\), sus errores son heterocedásticos por construcción y los contrastes de hipótesis pierden validez. Este capítulo desarrolla los modelos que resuelven estos problemas: el Probit y el Logit, presentados siempre junto al Modelo Lineal de Probabilidad (MPL) para entender exactamente en qué difieren y cuándo conviene usar cada uno.
2.2 El Modelo Lineal de Probabilidad
El Modelo Lineal de Probabilidad (MPL) es simplemente MCO aplicado a una variable dependiente binaria. El modelo es:
donde la probabilidad se modela como una función lineal de las covariables. La estimación es trivial — se usa lm() en R — y los coeficientes tienen una interpretación directa: \(\beta_j\) es el cambio en la probabilidad de \(y=1\) ante un incremento unitario de \(x_j\), manteniendo el resto constante.
El MPL tiene dos virtudes claras. En primer lugar, es transparente: los coeficientes son efectos marginales directos, no hay que calcular nada más. En segundo lugar, cuando las predicciones se sitúan mayoritariamente en el interior del intervalo \((0.2, 0.8)\), los resultados del MPL son muy similares a los del Probit o el Logit. Su uso es legítimo en esas condiciones, especialmente en datos de panel o con variables instrumentales donde los modelos no lineales son mucho más difíciles de implementar.
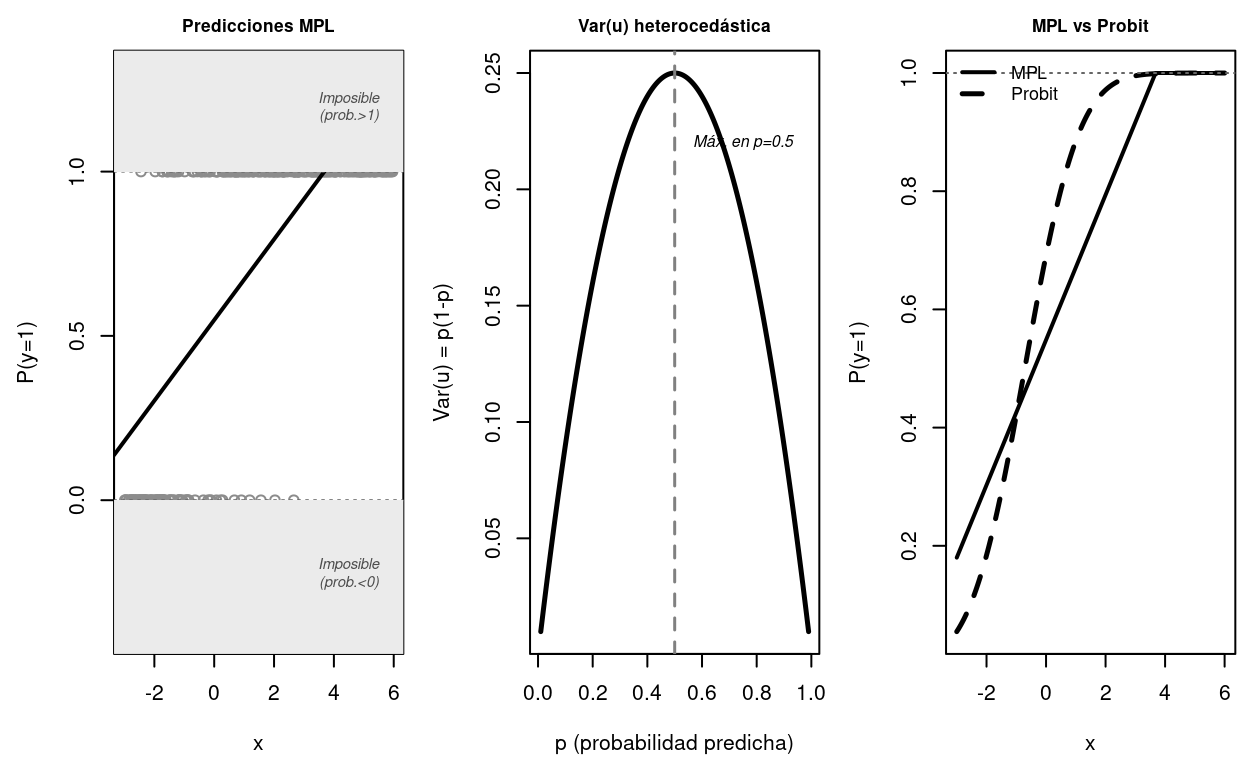
Sin embargo, el MPL tiene tres problemas serios. El primero y más visible: las predicciones pueden salir de \([0,1]\), produciendo “probabilidades” sin sentido. El segundo: los errores del modelo, \(u_i = y_i - \mathbf{x}_i'\boldsymbol{\beta}\), son heterocedásticos por construcción, con varianza \(\text{Var}(u_i) = p_i(1-p_i)\) que depende de \(\mathbf{x}_i\). Los errores estándar de MCO son incorrectos y hay que usar siempre errores robustos. El tercero: la relación entre las covariables y la probabilidad es lineal por supuesto, pero en realidad los datos muestran un efecto que se atenúa cerca de los extremos — la misma educación no tiene el mismo efecto sobre la probabilidad de trabajar si uno ya tiene probabilidad 0.95 que si la tiene de 0.5.
Figure 2.1: Los tres problemas del MPL. Panel izquierdo: predicciones fuera de [0,1] (zona gris). Panel central: heteroscedasticidad de los errores — la varianza p(1-p) varía con x y alcanza su máximo en p=0.5. Panel derecho: el MPL (línea sólida) subestima los efectos en los extremos en comparación con el Probit (línea discontinua).
La Figure 2.1 resume los tres problemas del MPL de forma visual. La solución pasa por utilizar modelos que garanticen que las predicciones caigan en \([0,1]\) y que capturen la no linealidad de la relación entre covariables y probabilidades: los modelos Probit y Logit.
2.3 El modelo Probit: derivación y estimación
2.3.1 El enfoque de variable latente
El modelo Probit parte del enfoque de variable latente introducido en el capítulo anterior. Supongamos que la utilidad neta de elegir \(y=1\) es:
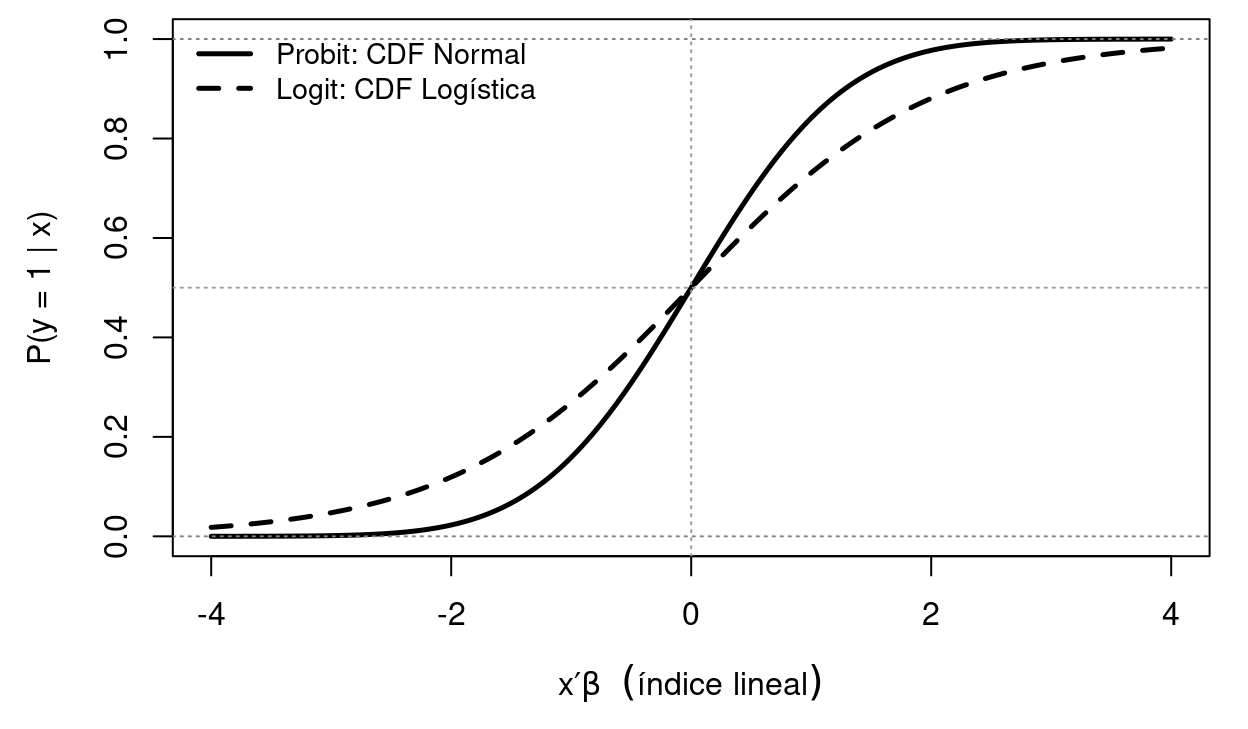
donde \(\Phi(\cdot)\) es la función de distribución acumulada de la Normal estándar. La simetría de la distribución Normal garantiza que \(1 - \Phi(-z) = \Phi(z)\). El resultado es una curva en forma de S que siempre produce probabilidades en \([0,1]\), como muestra la Figure 2.2.
2.3.2 La función de verosimilitud del Probit
Las \(n\) observaciones son independientes, y para cada una conocemos \(y_i \in \{0,1\}\). La función de verosimilitud es el producto de las probabilidades de haber observado exactamente lo que observamos:
El estimador Probit \(\hat{\boldsymbol{\beta}}\) maximiza esta log-verosimilitud. No existe solución analítica: la maximización se realiza numéricamente mediante algoritmos iterativos (Newton-Raphson o BFGS). Bajo condiciones de regularidad estándar, \(\hat{\boldsymbol{\beta}}\) es consistente y asintóticamente normal:
donde \(\mathbf{I}(\boldsymbol{\beta}) = -E\!\left[\partial^2 \ell/\partial\boldsymbol{\beta}\partial\boldsymbol{\beta}'\right]\) es la matriz de información de Fisher.
2.4 El modelo Logit: derivación y odds ratios
2.4.1 La distribución logística
El modelo Logit supone que el término de error de la ecuación latente sigue una distribución Logística estándar, con función de densidad:
La distribución Logística se parece mucho a la Normal estándar — ambas son simétricas alrededor de cero —, pero tiene colas más pesadas: la Logística asigna más probabilidad a valores extremos. Esto hace que el Logit sea ligeramente más conservador que el Probit en los extremos de la distribución.
Figure 2.2: Comparación entre la CDF Normal estándar (Probit, línea sólida) y la CDF Logística estándar (Logit, línea discontinua). Ambas producen curvas en S que garantizan probabilidades en [0,1]. La diferencia principal está en las colas: la Logística asigna ligeramente más probabilidad a los valores extremos.
2.4.2 La probabilidad Logit y la función log-odds
Con el supuesto Logístico, la probabilidad de observar \(y_i=1\) es:
Este resultado, que se conoce como log-odds o logit, demuestra que el Logit es un modelo lineal en los log-odds: el índice \(\mathbf{x}_i'\boldsymbol{\beta}\) no es la probabilidad sino el logaritmo del cociente de probabilidades. La interpretación directa del coeficiente \(\beta_j\) es el cambio en el log-odds ante un incremento unitario de \(x_j\). Una interpretación más intuitiva es la del odds ratio: \(\text{OR}_j = e^{\beta_j}\), que mide el factor multiplicativo por el que se multiplican los odds cuando \(x_j\) aumenta en una unidad.
Odds ratio \(\neq\) cambio en probabilidad. El odds y la probabilidad están relacionados de forma no lineal (\(P = \text{Odds}/(1+\text{Odds})\)). El OR te dice cuánto cambia la ventaja relativa; los efectos marginales te dicen cuánto cambia la probabilidad en puntos porcentuales. Son complementarios, no sustitutos.
2.4.3 La función de verosimilitud del Logit
Análogamente al Probit, la log-verosimilitud del Logit es:
Esta log-verosimilitud es cóncava en \(\boldsymbol{\beta}\), lo que garantiza un único máximo global. La estimación se realiza en R con glm(y ~ x, family = binomial(link = "logit")).
2.5 Efectos marginales: AME y MEM
Uno de los errores más frecuentes cuando se trabaja con modelos Probit y Logit es interpretar los coeficientes estimados \(\hat{\beta}_j\) como efectos sobre la probabilidad de \(y=1\). Esto es incorrecto. Los coeficientes de un Probit o un Logit son efectos sobre el índice lineal\(\mathbf{x}'\boldsymbol{\beta}\), no sobre la probabilidad. Para obtener el efecto sobre la probabilidad hay que calcular los efectos marginales.
2.5.1 Derivación matemática
Para el modelo Probit, la probabilidad de observar \(y=1\) es \(P(y=1|\mathbf{x}) = \Phi(\mathbf{x}'\boldsymbol{\beta})\). El efecto marginal de la variable \(x_j\) sobre esta probabilidad es:
donde el término \(\Lambda(z)[1-\Lambda(z)]\) es la función de densidad logística. Un resultado fundamental: el efecto marginal no es constante, sino que depende del punto \(\mathbf{x}\) donde se evalúa. Esto refleja la no linealidad intrínseca de estos modelos.
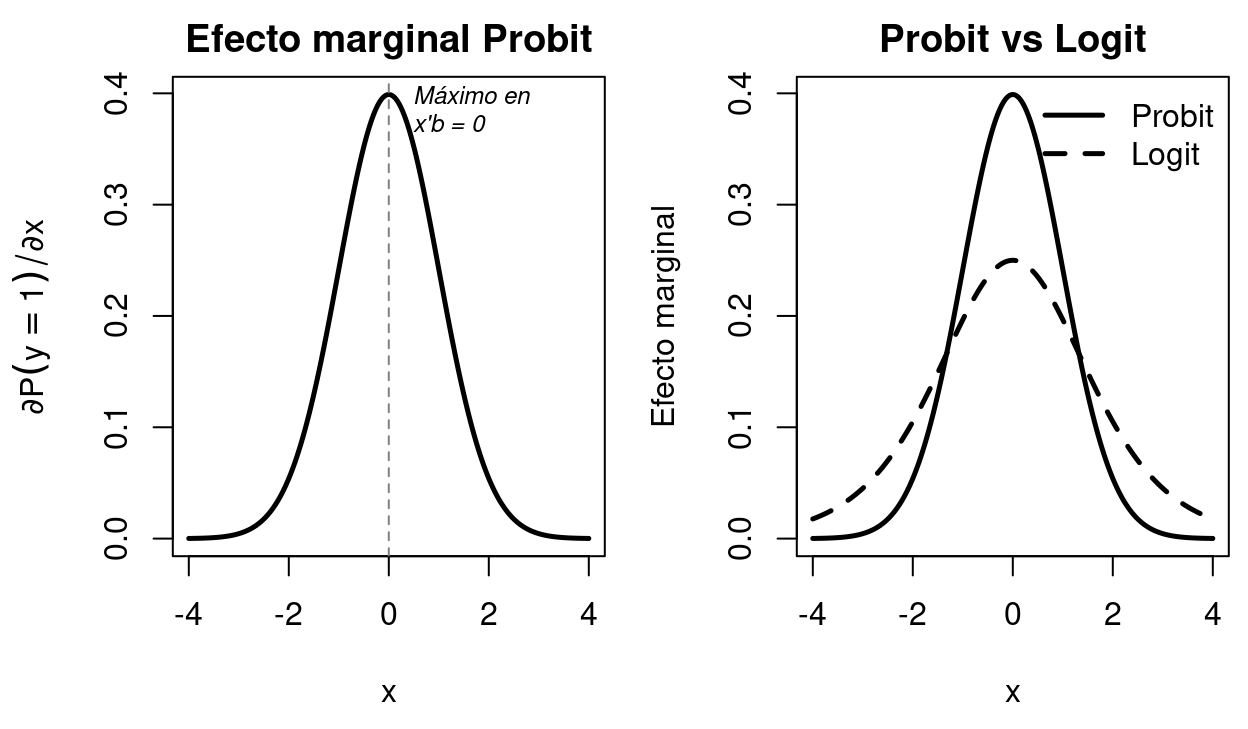
Figure 2.3: No linealidad de los efectos marginales. El efecto marginal de x sobre P(y=1) no es constante: es máximo cuando la probabilidad se sitúa en 0.5 (punto medio de la curva S) y se atenúa hacia los extremos. Izquierda: efecto marginal del Probit en función de x. Derecha: comparación del efecto marginal Probit vs Logit.
La Figure 2.3 muestra una característica fundamental de los modelos Probit y Logit: los efectos marginales no son constantes, sino que dependen del nivel de la probabilidad predicha. A diferencia de un modelo lineal, donde un cambio en una variable explicativa tiene siempre el mismo impacto sobre la variable dependiente, en estos modelos no lineales el efecto varía a lo largo de la distribución.
En el caso del Probit, el efecto marginal tiene forma de campana y alcanza su valor máximo cuando el índice lineal \(\mathbf{x}'\boldsymbol{\beta}\) es igual a cero, lo que corresponde a una probabilidad de 0.5. Este es el punto en el que el resultado es más incierto. En esa zona, pequeños cambios en las variables explicativas generan variaciones relativamente grandes en la probabilidad. A medida que nos alejamos de este punto y la probabilidad se aproxima a 0 o a 1, el efecto marginal disminuye progresivamente hasta acercarse a cero.
La intuición es que cuando la probabilidad está en valores intermedios, el sistema es más “sensible” a cambios en las variables explicativas, ya que el resultado no está claramente determinado. En cambio, cuando la probabilidad es muy alta o muy baja, el resultado está prácticamente decidido, por lo que cambios adicionales en las variables tienen un impacto muy limitado sobre la probabilidad.
La comparación entre Probit y Logit muestra que ambos modelos comparten esta misma lógica: el efecto marginal es máximo en el centro y se atenúa en los extremos. La diferencia principal es que en el modelo Probit el efecto está más concentrado alrededor del punto central, mientras que en el Logit se distribuye de forma más gradual, con colas más anchas. En cualquier caso, la implicación esencial es la misma: el impacto de una variable explicativa depende del nivel de la probabilidad predicha y, por tanto, no puede interpretarse como un efecto constante.
2.5.2 AME y MEM: dos formas de resumir el efecto marginal
Dado que el efecto marginal varía con \(\mathbf{x}\), necesitamos un número resumen que comunique el efecto “típico”. Hay dos convenciones:
El Efecto Marginal en la Media (MEM) evalúa el efecto en el individuo “promedio”, es decir, cuando todas las covariables toman sus valores medios:
donde \(f\) es \(\phi\) para el Probit y \(\lambda\) para el Logit. El MEM usa un individuo hipotético — el individuo promedio — que puede no existir en la muestra.
El Efecto Marginal Promedio (AME, Average Marginal Effect) promedia los efectos marginales individuales calculados para cada observación de la muestra:
El AME es la medida más recomendada en la literatura actual porque refleja el efecto promedio sobre el conjunto real de individuos de la muestra, no sobre un individuo hipotético. En la mayoría de aplicaciones, AME y MEM son similares, pero pueden diferir cuando la distribución de covariables es muy asimétrica.
2.6 Modelo ilustrativo: participación laboral
Para desarrollar el análisis completo de forma concreta, trabajaremos con el dataset de participación laboral (participacion_laboral.csv), que contiene información sobre 500 personas en edad activa. La variable dependiente es trabaja (1 si la persona está empleada, 0 si no), y las covariables son educación, edad, sexo (Hombre/Mujer), número de hijos e ingreso familiar.
Antes de estimar cualquier modelo, verificamos la estructura y realizamos un EDA breve. La Table 2.1 presenta los estadísticos descriptivos del dataset.
Table 2.1: Estadísticos descriptivos del dataset de participación laboral. La tasa de empleo es del 75.2%. Se observa que los empleados tienen mayor educación y experiencia que los no empleados, coherente con la teoría del capital humano.
Variable
Media
D.T.
Mín.
Máx.
Educación (años)
13.20
4.17
6
20.0
Edad
41.66
13.01
18
65.0
Hijos
1.26
1.17
0
4.0
Experiencia (años)
22.60
13.68
0
53.0
Ingreso familiar (€m)
10.19
5.64
0
26.5
Nota:
n=500 | Tasa de empleo: 75.2%.
2.6.1 Estimación comparada: MPL, Probit y Logit
Estimamos los tres modelos para el mismo conjunto de covariables: educación, edad, sexo (dummy hombre=1), número de hijos e ingreso familiar. Los resultados se presentan en la Table 2.2.
Table 2.2: Comparación de estimaciones MPL, Probit y Logit para el modelo de participación laboral. Los coeficientes del MPL son efectos marginales directos sobre la probabilidad. Los coeficientes de Probit y Logit son efectos sobre el índice lineal (no sobre la probabilidad) y no son comparables en magnitud entre sí ni con el MPL.
Variable
MPL (EE robustos)
Probit
Logit
Constante
-0.0481 (0.0942)
-2.2756*** (0.3727)
-3.9772*** (0.6618)
Educación
0.0221*** (0.0041)
0.0924*** (0.0172)
0.1576*** (0.0306)
Edad
0.0137*** (0.0013)
0.0536*** (0.0060)
0.0944*** (0.0110)
Hombre (=1)
0.0868* (0.0344)
0.3457* (0.1409)
0.6439** (0.2477)
N.º hijos
-0.0433** (0.0154)
-0.1837** (0.0585)
-0.3110** (0.1024)
Ingreso familiar
-0.0054· (0.0030)
-0.0233· (0.0124)
-0.0433* (0.0216)
Nota:
***p<.001, **p<.01, *p<.05. Error estándar entre paréntesis.
La Table 2.2 muestra los coeficientes de los tres modelos. Los signos son consistentes: educación, edad y ser hombre aumentan la probabilidad de empleo, mientras que el número de hijos y el ingreso familiar la reducen. Sin embargo, las magnitudes no son comparables entre modelos porque miden cosas distintas: el MPL mide directamente el cambio en la probabilidad, mientras que Probit y Logit miden el cambio en el índice latente. Para comparar los efectos sobre la probabilidad hay que calcular los efectos marginales.
2.6.2 Efectos marginales AME y MEM
El siguiente paso fundamental es calcular los efectos marginales. Calculamos tanto el AME como el MEM para el modelo Probit y presentamos también los odds ratios del Logit.
Code
coefs_p <-coef(probit)X_mat <-model.matrix(probit)x_means <-colMeans(X_mat)# AME Probit: media de phi(x'beta) * beta_j para cada obs.phi_vals <-dnorm(X_mat %*% coefs_p)ame_probit <-colMeans(as.numeric(phi_vals) * X_mat) *1# = mean(phi)*beta_j# Corrección: AME_j = mean(phi(x_i'b)) * beta_jame_vals <-mean(phi_vals) * coefs_p# MEM Probit: phi(x_bar'beta) * beta_jphi_mean <-dnorm(sum(x_means * coefs_p))mem_vals <- phi_mean * coefs_pvars_use <-c("educacion","edad","hombre","hijos","ingreso_familiar")labs_use <-c("Educación (años)","Edad","Hombre (=1)","N.º hijos","Ingreso familiar")df_ame <-data.frame(Variable = labs_use,AME =sprintf("%.4f", ame_vals[vars_use]),MEM =sprintf("%.4f", mem_vals[vars_use]))kbl(df_ame, booktabs=TRUE, row.names=FALSE, align=c("l","r","r"),col.names=c("Variable","AME (Probit)","MEM (Probit)")) |>kable_styling(latex_options=c("hold_position"),bootstrap_options=c("condensed","striped"), full_width=FALSE) |>footnote(general="Valores en escala de probabilidad. Multiplicar ×100 para obtener p.p.",general_title="Nota:", footnote_as_chunk=FALSE)
Table 2.3: Efectos marginales del modelo Probit sobre la probabilidad de empleo. El AME promedia el efecto sobre todos los individuos de la muestra; el MEM evalúa el efecto en el individuo con los valores medios de todas las covariables. Las diferencias entre AME y MEM son pequeñas en este caso, lo que indica que la distribución de las covariables es razonablemente simétrica.
Variable
AME (Probit)
MEM (Probit)
Educación (años)
0.0221
0.0248
Edad
0.0128
0.0144
Hombre (=1)
0.0827
0.0927
N.º hijos
-0.0439
-0.0493
Ingreso familiar
-0.0056
-0.0063
Nota:
Valores en escala de probabilidad. Multiplicar ×100 para obtener p.p.
La Table 2.3 revela que un año adicional de educación aumenta la probabilidad de empleo en aproximadamente 2.2 puntos porcentuales (AME Probit). Ser hombre (frente a mujer) aumenta la probabilidad en 8.3 puntos. Cada hijo adicional reduce la probabilidad en 4.4 puntos.
2.6.3 Odds ratios del modelo Logit
Una ventaja exclusiva del modelo Logit es que sus coeficientes permiten calcular odds ratios con una interpretación multiplicativa directa: \(\text{OR}_j = e^{\hat\beta_j}\) mide el factor por el que se multiplican los odds de \(y=1\) cuando \(x_j\) aumenta en una unidad.
Table 2.4: Odds ratios del modelo Logit para la participación laboral. Un OR > 1 indica que la variable aumenta los odds de empleo; un OR < 1 que los reduce. Un año más de educación multiplica los odds de empleo por 1.22, lo que equivale a un aumento del 22%.
Variable
OR
IC inf 95%
IC sup 95%
Interpretación
Educación (años)
1.171
1.104
1.245
+17% odds
Edad
1.099
1.076
1.124
+10% odds
Hombre (=1)
1.904
1.177
3.113
+90% odds
N.º hijos
0.733
0.598
0.894
-27% odds
Ingreso familiar
0.958
0.918
0.999
-4% odds
Nota:
IC al 95% con perfil de verosimilitud.
2.6.4 Significación individual y conjunta
La significación individual de cada coeficiente se evalúa con el estadístico z (ratio del coeficiente entre su error estándar), que bajo la hipótesis nula \(H_0: \beta_j=0\) sigue asintóticamente una distribución \(N(0,1)\). La Table 2.2 ya incluye los \(p\)-valores de estos contrastes.
Para la significación conjunta del modelo completo frente al modelo nulo (solo constante), utilizamos el test de Razón de Verosimilitudes (LR):
Table 2.5: Bondad del ajuste y test LR para los tres modelos. El Pseudo-R² de McFadden compara la log-verosimilitud del modelo con la del modelo nulo (solo constante). La tabla de clasificación muestra el porcentaje de observaciones correctamente clasificadas con umbral de 0.5.
Medida
MPL
Probit
Logit
Log-verosimilitud
-221.3
-213.0
-212.8
McFadden R²
—
0.2394
0.2403
Test LR (vs nulo)
—
134.1
134.6
p-valor LR
—
<0.001
<0.001
% clasificados correctamente
80.4%
81.0%
81.0%
AIC
456.5
438.0
437.5
La Table 2.5 muestra que los tres modelos tienen un ajuste similar. El Pseudo-R² de McFadden, cuya interpretación es análoga al \(R^2\) ordinario aunque con escala diferente, se sitúa en torno a 0.2 para Probit y Logit, un valor que en la práctica se considera un ajuste razonablemente bueno para modelos de elección binaria. El test LR rechaza con claridad la hipótesis nula de que todas las pendientes son cero.
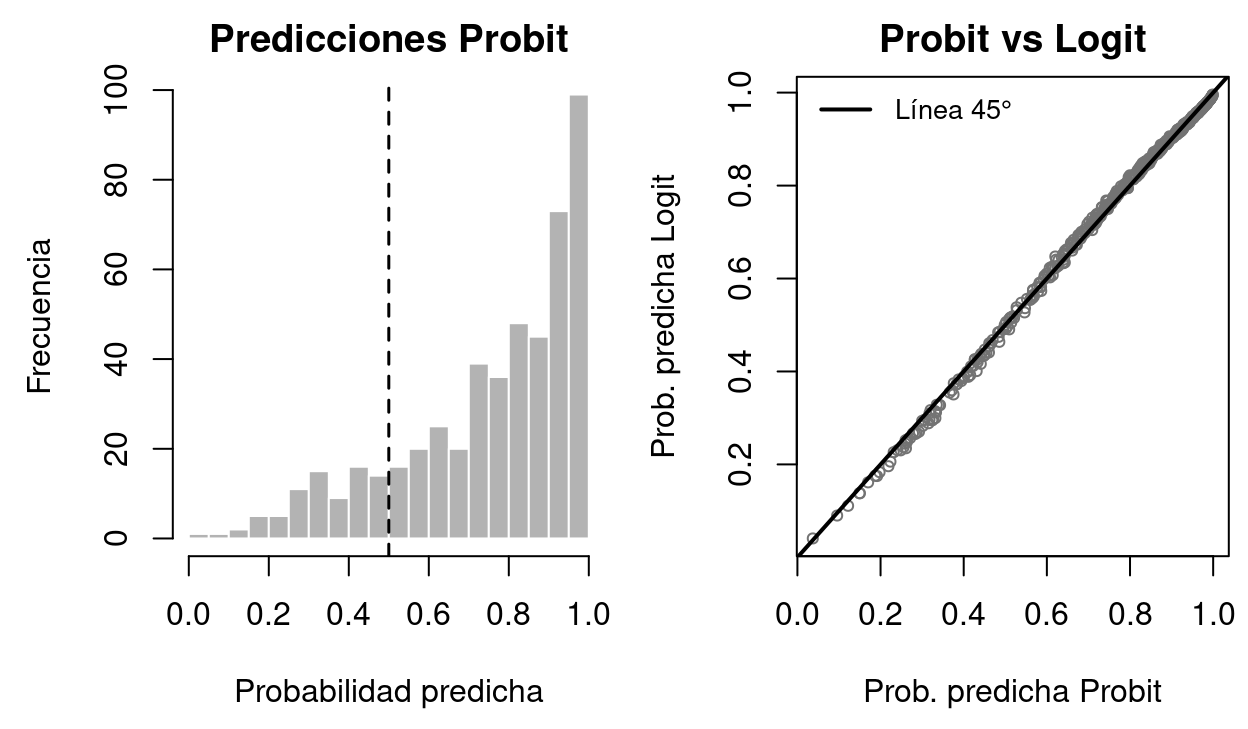
Figure 2.4: Distribución de las probabilidades predichas por el modelo Probit (panel izquierdo) y comparación de las predicciones de los tres modelos (panel derecho). El modelo Probit y el Logit producen distribuciones de probabilidades casi idénticas, mientras que el MPL presenta una distribución más dispersa con algunos valores fuera de [0,1].
2.7 Comparación final: MPL, Probit y Logit
Una pregunta práctica frecuente es: ¿qué modelo usar? La respuesta depende del contexto y de los objetivos del análisis.
El MPL es preferible cuando la variable dependiente tiene una tasa de eventos entre el 20% y el 80%, cuando el objetivo es solo cuantificar un efecto marginal promedio sin importar las predicciones individuales, o cuando el modelo se va a estimar con efectos fijos, variables instrumentales o en un contexto de diferencias en diferencias donde la no linealidad complica mucho la implementación. Sus errores estándar deben ser siempre robustos.
El Probit es la elección natural cuando el proceso generador de datos tiene una interpretación de variable latente con errores normales, lo que es habitual en modelos de utilidad aleatoria. Es el más utilizado en microeconomía teórica aplicada.
El Logit es conveniente cuando se desean los odds ratios como medida de efecto (frecuente en epidemiología, finanzas y marketing), cuando la muestra es pequeña (el Logit tiene propiedades numéricas más estables) o cuando se trabaja con datos de panel con efectos fijos binarios (el Logit condicional es la única opción coherente).
Code
df_comp <-data.frame(Criterio =c("Coeficientes son efectos marginales directos","Garantiza predicciones en [0,1]","Permite odds ratios","Apto para efectos fijos de panel","Interpretación de variable latente","Errores estándar robustos necesarios"),MPL =c("Sí","No","No","Sí (con FWL)","No","Siempre"),Probit =c("No (necesita ME)","Sí","No","Difícil","Sí (Normal)","No"),Logit =c("No (necesita ME)","Sí","Sí","Sí (condicional)","Sí (Logística)","No"),check.names=FALSE)kbl(df_comp, booktabs=TRUE, row.names=FALSE, align=c("l","c","c","c"),col.names=c("Criterio","MPL","Probit","Logit")) |>kable_styling(latex_options=c("hold_position","scale_down"),bootstrap_options=c("condensed","striped"), full_width=FALSE)
Table 2.6: Resumen de las propiedades y recomendaciones de uso de los tres modelos de elección binaria. Todos producen estimaciones consistentes cuando el modelo está correctamente especificado; las diferencias son sobre todo de conveniencia interpretativa.
Criterio
MPL
Probit
Logit
Coeficientes son efectos marginales directos
Sí
No (necesita ME)
No (necesita ME)
Garantiza predicciones en [0,1]
No
Sí
Sí
Permite odds ratios
No
No
Sí
Apto para efectos fijos de panel
Sí (con FWL)
Difícil
Sí (condicional)
Interpretación de variable latente
No
Sí (Normal)
Sí (Logística)
Errores estándar robustos necesarios
Siempre
No
No
2.8 Casos prácticos
Los tres casos prácticos de este capítulo aplican el análisis completo desarrollado en las secciones anteriores a contextos económicos diferentes: la concesión de crédito bancario, la decisión de compra en comercio electrónico y la matrícula universitaria. En cada caso el alumno debe ser capaz de: identificar la variable dependiente y su tipo, estimar los tres modelos, calcular e interpretar los efectos marginales, obtener y comentar los odds ratios del Logit y evaluar la bondad del ajuste.
2.8.1 Caso práctico 1: Concesión de crédito bancario
Contexto. El dataset CP01 contiene 700 solicitudes de crédito bancario. La variable dependiente concesion vale 1 si el banco aprueba la solicitud y 0 si la deniega. La tasa de aprobación es del 42.4%. Las covariables recogen las características del solicitante relevantes para la evaluación de riesgo: nivel de ingresos (€ miles/mes), historial crediticio (1=bueno), ratio de deuda sobre ingresos, años de experiencia laboral, existencia de garantía y edad.
Table 2.7: Resultados del modelo Logit para la concesión de crédito bancario (CP01). El historial crediticio y la garantía son los predictores con mayor efecto marginal. Un ratio de deuda elevado reduce fuertemente la probabilidad de aprobación.
Variable
Coef. Logit
Odds Ratio
AME Logit
Ingreso (€m)
0.055
1.057
0.0084
Hist. crediticio (=1)
1.033
2.810
0.1565
Ratio deuda/ingreso
-3.824
0.022
-0.5793
Experiencia laboral (años)
0.078
1.081
0.0118
Garantía (=1)
0.970
2.638
0.1470
Edad
0.019
1.019
0.0028
Nota:
n=700 | Aprobación: 42.4% | McFadden R²=0.319.
La Table 2.7 confirma que el historial crediticio y la garantía son los determinantes más potentes de la aprobación del crédito. Un historial bueno multiplica los odds de aprobación por 2.81, mientras que contar con garantía los multiplica por 2.64. El ratio de deuda/ingresos tiene el efecto contrario más intenso: cada punto adicional en este ratio reduce sustancialmente la probabilidad de aprobación. El alumno puede reproducir y ampliar este análisis con el siguiente script:
T02_CP01_mECO_Logit_Credito.R
2.8.2 Caso práctico 2: Decisión de compra online
Contexto. El dataset CP02 recoge 600 sesiones de navegación en una tienda de comercio electrónico. La variable dependiente compra vale 1 si la sesión termina en compra y 0 si el usuario abandona sin comprar. La tasa de conversión es del 36%, coherente con los valores habituales en e-commerce. Las covariables son: tiempo de sesión (minutos), número de visitas previas al sitio, porcentaje de descuento aplicado, edad del usuario, sexo (mujer=1) e ingreso mensual.
Code
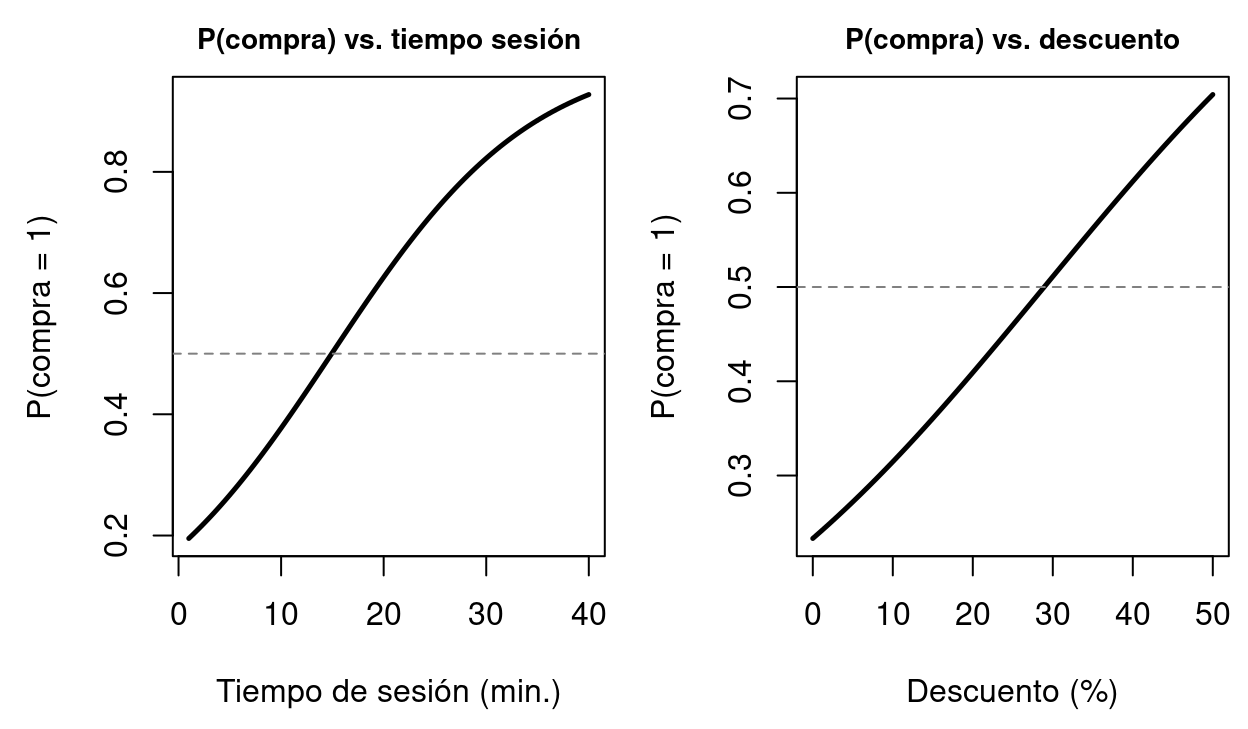
load("data/T02_CP02_compra_online.RData")logit_c2 <-glm(compra ~ tiempo_sesion + visitas_previas + descuento + edad + sexo + ingreso_mensual,data=ecommerce, family=binomial(link="logit"))par(mfrow=c(1,2), mar=c(4.5,4.5,2,0.5), cex.main=0.88)# Prob. vs tiempo_sesiont_seq <-seq(1, 40, length.out=100)nd1 <-data.frame(tiempo_sesion=t_seq,visitas_previas=mean(ecommerce$visitas_previas),descuento=mean(ecommerce$descuento),edad=mean(ecommerce$edad),sexo=mean(ecommerce$sexo),ingreso_mensual=mean(ecommerce$ingreso_mensual))p1 <-predict(logit_c2, newdata=nd1, type="response")plot(t_seq, p1, type="l", lwd=2.5, lty=1,xlab="Tiempo de sesión (min.)", ylab="P(compra = 1)",main="P(compra) vs. tiempo sesión")abline(h=0.5, lty=2, col=gray(0.5))# Prob. vs descuentod_seq <-seq(0, 50, by=1)nd2 <-data.frame(tiempo_sesion=mean(ecommerce$tiempo_sesion),visitas_previas=mean(ecommerce$visitas_previas),descuento=d_seq,edad=mean(ecommerce$edad),sexo=mean(ecommerce$sexo),ingreso_mensual=mean(ecommerce$ingreso_mensual))p2 <-predict(logit_c2, newdata=nd2, type="response")plot(d_seq, p2, type="l", lwd=2.5, lty=1,xlab="Descuento (%)", ylab="P(compra = 1)",main="P(compra) vs. descuento")abline(h=0.5, lty=2, col=gray(0.5))par(mfrow=c(1,1))
Figure 2.5: Probabilidad de compra online en función del tiempo de sesión y el descuento aplicado (CP02). Panel izquierdo: a mayor tiempo de sesión, mayor probabilidad de compra (curva Logit). Panel derecho: el descuento tiene un efecto positivo pero decreciente sobre la probabilidad de conversión.
La Figure 2.5 ilustra un resultado fundamental de los modelos Logit: el efecto sobre la probabilidad de conversión no es lineal. El tiempo de sesión tiene un efecto que se va saturando — a partir de cierto tiempo, aumentar más la navegación ya no incrementa mucho la probabilidad de compra. De forma análoga, el descuento también tiene retornos decrecientes. El alumno puede explorar estos efectos de forma interactiva con el siguiente script:
T02_CP02_mECO_Logit_Compra.R
2.8.3 Caso práctico 3: Matrícula universitaria
Contexto. El dataset CP03 contiene 650 estudiantes de bachillerato que han solicitado acceso a la universidad. La variable matricula vale 1 si finalmente se matriculan y 0 si no lo hacen. La tasa de matriculación es del 55.7%. Las covariables son: nota de acceso (PAU, 4-10), ingreso familiar, distancia al campus en km, si tiene beca disponible, si el padre tiene estudios universitarios y sexo del estudiante.
Table 2.8: Efectos marginales AME del modelo Probit para la matrícula universitaria (CP03). La nota de acceso y la disponibilidad de beca son los predictores más importantes. La distancia al campus tiene un efecto negativo significativo que se atenúa con mayor nota.
Variable
Coef. Probit
AME
AME (pp)
Nota acceso PAU (4-10)
0.3394
0.1049
10.49 pp
Ingreso familiar (€m)
0.0199
0.0061
0.61 pp
Distancia al campus (km)
-0.0047
-0.0015
-0.15 pp
Beca disponible (=1)
0.7507
0.2320
23.20 pp
Padre universitario (=1)
0.4195
0.1296
12.96 pp
Mujer (=1)
0.1604
0.0496
4.96 pp
Nota:
n=650 | Matriculación: 55.7% | pp = puntos porcentuales.
La Table 2.8 revela que un punto adicional en la nota de acceso aumenta la probabilidad de matriculación en 10.5 puntos porcentuales. La disponibilidad de beca tiene el efecto más intenso de todas las variables: aumenta la probabilidad en 23.2 puntos porcentuales, lo que subraya la importancia de la financiación en la decisión de acceso a la educación superior. La distancia tiene un efecto negativo pero moderado. El alumno puede reproducir este análisis completo de forma interactiva con el siguiente script:
T02_CP03_mECO_Logit_Matricula.R
2.9 Guía de comandos R para este capítulo
2.9.1 glm() con family = binomial — Estimación Probit y Logit
La función glm() (Generalized Linear Model) es el instrumento fundamental para estimar modelos de variable dependiente binaria en R. Al especificar family = binomial, R utiliza MLE en lugar de MCO y garantiza que las predicciones pertenezcan al intervalo \([0,1]\). La elección entre Probit y Logit se controla con el argumento link.
Los parámetros principales son: la fórmula y ~ x1 + x2 + ... especifica la variable dependiente y las covariables; data indica el dataframe que contiene los datos; family = binomial(link = "probit") activa el modelo Probit (función de enlace normal); family = binomial(link = "logit") activa el modelo Logit (función de enlace logística). El objeto resultante tiene clase glm y permite acceder a coeficientes con coef(), predicciones con fitted() y estadísticos con summary().
2.9.2 lm() + coeftest(vcovHC()) — Modelo Lineal de Probabilidad (MPL) con errores robustos
El MPL se estima con la función lm() estándar de MCO. Sin embargo, sus errores estándar son inválidos por la heterocedasticidad inherente del modelo binario, por lo que es obligatorio corregirlos con coeftest() del paquete lmtest, pasando una estimación robusta de la matriz de varianzas calculada por vcovHC() del paquete sandwich.
library(lmtest); library(sandwich)mpl <-lm(trabaja ~ educacion + edad + hijos, data = df)coeftest(mpl, vcov =vcovHC(mpl, type ="HC1"))
El argumento type = "HC1" selecciona el estimador heterocedástico consistente HC1, el más habitual en econometría aplicada. Alternativas más conservadoras son "HC3" y "HC4", que tienden a producir errores estándar algo mayores. coeftest() devuelve una tabla con coeficientes, errores estándar robustos, estadísticos \(t\) y \(p\)-valores.
2.9.3 exp(coef()) — Odds Ratios del modelo Logit
Los coeficientes del modelo Logit se interpretan en escala de log-odds, que no es intuitiva. Para transformarlos en odds ratios (ORs) con interpretación multiplicativa basta con aplicar la exponencial. Un OR > 1 indica que la variable aumenta los odds del evento; un OR < 1 indica que los reduce.
exp(coef(logit)) # odds ratios puntualesexp(confint(logit, level =0.95)) # IC al 95% de los OR
coef(logit) extrae el vector de coeficientes estimados. confint(logit) calcula los intervalos de confianza en escala log-odds mediante perfil de verosimilitud, y exp() los convierte a OR. Por ejemplo, un OR de 1.22 para educacion significa que cada año adicional de educación multiplica los odds de empleo por 1.22 (+22%).
2.9.4 Efectos marginales AME y MEM — Cálculo directo con derivadas
Los coeficientes de Probit y Logit son efectos sobre el índice lineal \(\mathbf{x}'\boldsymbol{\beta}\), no sobre la probabilidad. El efecto marginal sobre la probabilidad requiere multiplicar el coeficiente por la densidad de la función de enlace evaluada en \(\mathbf{x}'\hat{\boldsymbol{\beta}}\). El AME promedia este producto sobre todos los individuos de la muestra; el MEM lo evalúa en el individuo con los valores medios de todas las covariables.
# AME Probit (usar dnorm, la densidad de la Normal estándar)ame_probit <-mean(dnorm(predict(probit))) *coef(probit)["educacion"]# MEM Probit (evaluar la densidad en la media de las covariables)phi_media <-dnorm(sum(colMeans(model.matrix(probit)) *coef(probit)))mem_probit <- phi_media *coef(probit)["educacion"]# AME Logit (usar dlogis, la densidad de la distribución Logística)ame_logit <-mean(dlogis(predict(logit))) *coef(logit)["educacion"]
dnorm() es la densidad de la distribución Normal estándar, usada para el Probit. dlogis() es la densidad de la distribución Logística estándar, usada para el Logit. predict(modelo) devuelve el predictor lineal \(\mathbf{x}_i'\hat{\boldsymbol{\beta}}\) para cada observación de la muestra. model.matrix(modelo) extrae la matriz de diseño completa incluyendo la columna de intercepto.
2.9.5 logLik() y pchisq() — Test LR y Pseudo-R² de McFadden
El test de Razón de Verosimilitudes (LR) contrasta si el modelo estimado mejora significativamente el ajuste respecto al modelo nulo (solo constante). El Pseudo-R² de McFadden cuantifica esa mejora relativa en una escala de 0 a 1.
# Modelo nulo (solo constante)nulo <-glm(trabaja ~1, data = df, family = binomial)# Test LRLR <--2* (as.numeric(logLik(nulo)) -as.numeric(logLik(probit)))p_valor <-pchisq(LR, df =length(coef(probit)) -1, lower.tail =FALSE)# Pseudo-R² de McFaddenR2_McF <-1-as.numeric(logLik(probit)) /as.numeric(logLik(nulo))
logLik() devuelve la log-verosimilitud maximizada del modelo. pchisq(..., lower.tail = FALSE) calcula el p-valor del test LR: bajo \(H_0\) (todas las pendientes son cero), el estadístico LR sigue asintóticamente una \(\chi^2\) con tantos grados de libertad como covariables tiene el modelo. El Pseudo-R² de McFadden oscila entre 0 y 1: valores entre 0.20 y 0.40 se consideran un ajuste razonablemente bueno en modelos binarios.
Los scripts de este capítulo están disponibles en la carpeta scripts/ del repositorio del manual, en: