Las variables cualitativas — también llamadas categóricas — son aquellas que clasifican a los individuos en categorías no numéricas: sexo, estado civil, sector económico, nivel educativo, comunidad autónoma. A diferencia de las variables cuantitativas (salario, edad, producción), no pueden incluirse directamente en una ecuación de regresión. Sin embargo, son omnipresentes en los datos económicos y contienen información esencial. Este capítulo aborda dos cuestiones distintas pero complementarias.
La primera parte estudia cómo utilizar variables cualitativas como regresores (variables explicativas): las variables ficticias o dummies, los modelos ANOVA y ANCOVA. Esta es la situación más frecuente en la práctica: queremos saber si el salario difiere entre hombres y mujeres, o entre sectores económicos, controlando por otras variables.
La segunda parte estudia una situación más avanzada: cuando la propia variable dependiente es cualitativa con más de dos categorías. Un consumidor elige entre coche, autobús o tren; un alumno califica su satisfacción de 1 a 5. Estos modelos — Logit Multinomial y Probit/Logit Ordenado — generalizan los modelos binarios del Tema 2 a múltiples categorías.
8.2 PARTE I: Variables cualitativas como regresores
8.2.1 Variables ficticias (dummies)
Una variable ficticia o dummy es una variable binaria que toma el valor 1 si el individuo pertenece a una categoría y 0 si no. Si una variable cualitativa tiene \(K\) categorías, se necesitan \(K - 1\) dummies para representarla (la categoría omitida es la categoría de referencia o base). Incluir las \(K\) dummies generaría multicolinealidad perfecta — la trampa de la variable ficticia.
Consideremos el ejemplo más simple: el efecto del sexo sobre el salario. Definimos \(D_i = 1\) si el individuo es mujer y \(D_i = 0\) si es hombre. El modelo es:
El coeficiente \(\beta_0\) es el salario medio de los hombres (categoría base: \(D=0\)). El coeficiente \(\beta_1\) es la diferencia salarial entre mujeres y hombres. Si \(\beta_1 = -200\), las mujeres ganan en promedio 200 euros menos que los hombres, manteniendo constantes las demás variables.
Cuando hay más de dos categorías — por ejemplo, nivel educativo (primaria, secundaria, universidad) —, se crean \(K-1 = 2\) dummies:
donde \(\beta_0\) es el salario medio con educación primaria (base), \(\beta_1\) es la diferencia de secundaria respecto a primaria, y \(\beta_2\) la diferencia de universidad respecto a primaria.
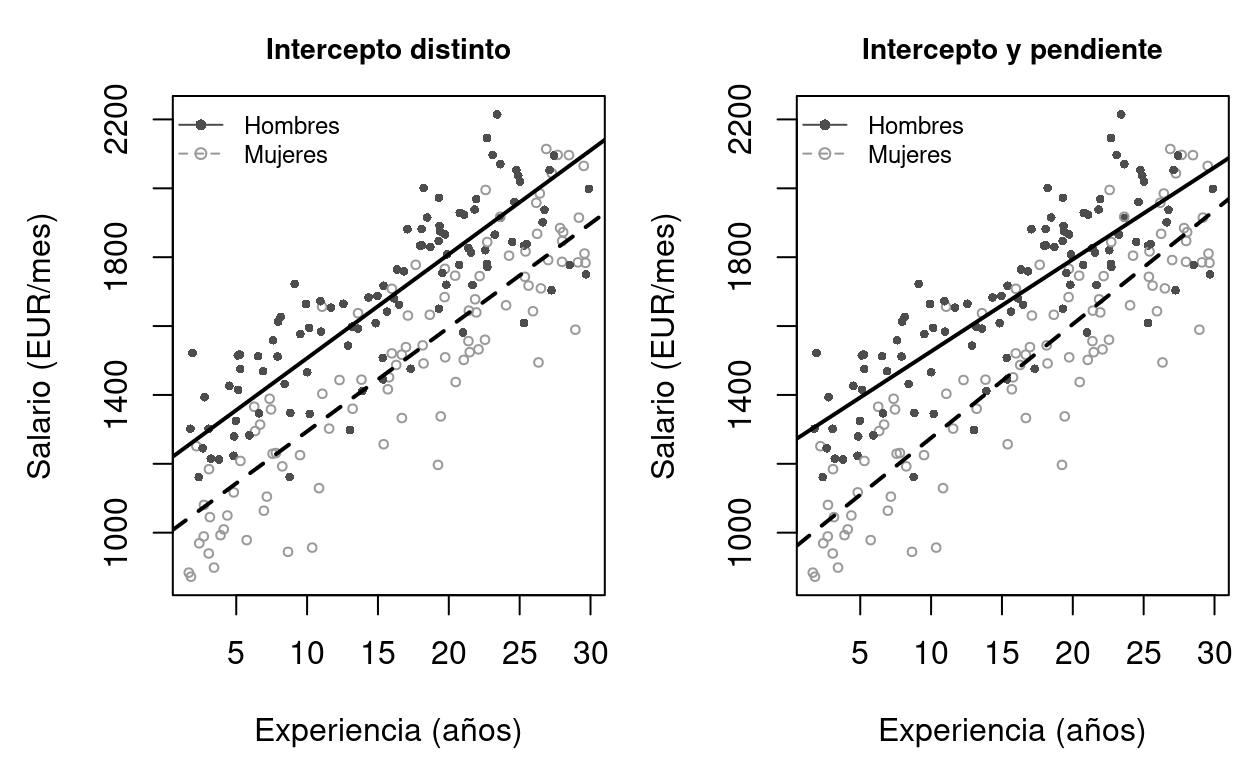
Figure 8.1: Efecto de las variables dummy en la regresión. Izquierda: una dummy de sexo desplaza el intercepto (líneas paralelas). Derecha: se puede añadir una interacción con la experiencia para permitir pendientes distintas.
El panel izquierdo muestra el modelo aditivo: la dummy desplaza el intercepto sin cambiar la pendiente (líneas paralelas). El panel derecho incluye una interacción entre la dummy y la experiencia (\(D \times \text{experiencia}\)), lo que permite que la pendiente también difiera entre grupos.
8.2.2 Interacciones y cambio estructural
La interacción \(D_i \times x_i\) permite que el efecto de \(x\) difiera según el grupo:
Para el grupo base (\(D=0\)): \(E[y] = \beta_0 + \beta_2 x\). Para el grupo tratado (\(D=1\)): \(E[y] = (\beta_0 + \beta_1) + (\beta_2 + \beta_3) x\). El coeficiente \(\beta_3\) mide si la pendiente difiere entre grupos. Si \(\beta_3 \neq 0\), hay cambio estructural — el efecto de \(x\) sobre \(y\) no es el mismo para ambos grupos.
El test de Chow contrasta formalmente si todos los coeficientes difieren entre grupos. Es equivalente a un test F que compara el modelo restringido (sin dummies ni interacciones) con el modelo completo.
8.2.3 Modelos ANOVA
El análisis de la varianza (ANOVA) es un caso particular de regresión donde todas las variables explicativas son cualitativas (dummies). Su objetivo es determinar si las medias de la variable dependiente difieren significativamente entre grupos.
En un ANOVA de una vía con \(K\) grupos, el modelo es:
donde \(\mu\) es la media global y \(\alpha_k\) es el efecto del grupo \(k\). El contraste \(H_0: \alpha_1 = \alpha_2 = \cdots = \alpha_K = 0\) se realiza con el estadístico F:
\[F = \frac{SCE/(K-1)}{SCR/(n-K)} = \frac{\text{Varianza entre grupos}}{\text{Varianza dentro de los grupos}}\]
Si \(F\) es grande (la variación entre grupos es mucho mayor que la variación dentro), rechazamos \(H_0\) y concluimos que al menos un grupo tiene media distinta.
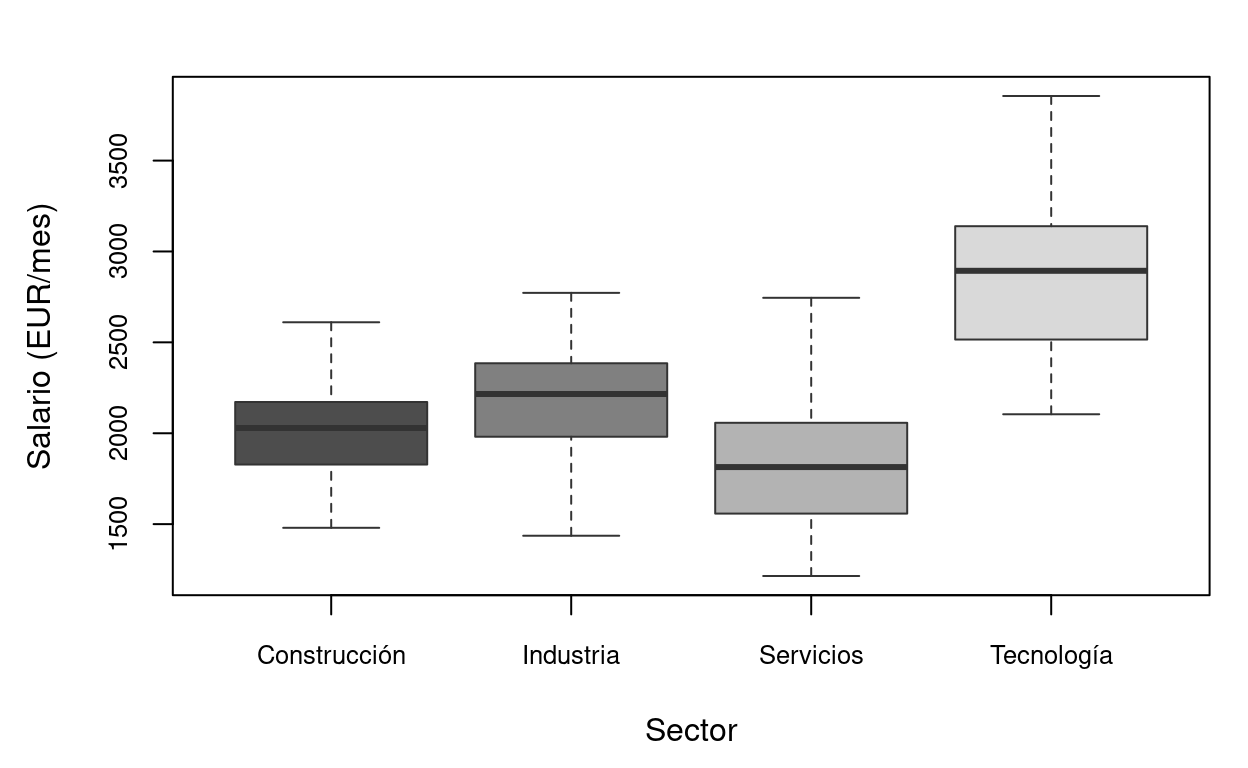
Figure 8.2: ANOVA de una vía: salarios por sector económico. Las cajas muestran la distribución de salarios en cada sector. Las diferencias entre medianas (líneas horizontales gruesas) son lo que el test F de ANOVA contrasta.
En el ejemplo del gráfico, el sector Tecnología tiene salarios claramente más altos. El ANOVA contrasta si estas diferencias son estadísticamente significativas.
En un ANOVA de dos vías se incluyen dos variables cualitativas simultáneamente — por ejemplo, sector y nivel educativo. Esto permite separar el efecto de cada factor y, opcionalmente, su interacción.
8.2.4 Modelos ANCOVA
El análisis de la covarianza (ANCOVA) combina variables cualitativas (dummies) y cuantitativas (covariables continuas) en el mismo modelo. Es la situación más habitual en econometría aplicada:
ANCOVA permite comparar las medias entre grupos controlando por las covariables continuas. Por ejemplo, comparar salarios entre hombres y mujeres controlando por experiencia, educación y sector. Sin este control, la diferencia bruta podría reflejar diferencias en características (las mujeres tienen menor experiencia media) y no discriminación pura.
8.3 PARTE II: Variable dependiente cualitativa
8.3.1 Más allá de la elección binaria
En el Tema 2 estudiamos modelos para variables dependientes binarias (Logit y Probit). Muchas decisiones económicas, sin embargo, involucran más de dos alternativas. Un trabajador elige entre empleo, desempleo o inactividad. Un consumidor elige entre coche, autobús o tren. Un banco asigna una calificación de riesgo (AAA, AA, A, BBB, …). La distinción clave es entre variables nominales (sin orden: medios de transporte) y ordinales (con orden: satisfacción, calificación crediticia).
8.3.2 El Logit Multinomial
Supongamos que el individuo \(i\) elige entre \(J\) alternativas mutuamente excluyentes. Bajo el marco de utilidad aleatoria de McFadden (1974), cada alternativa \(j\) proporciona una utilidad:
El individuo elige la alternativa que maximiza su utilidad. Si los errores \(\varepsilon_{ij}\) siguen independientemente una distribución Gumbel (valor extremo tipo I), las probabilidades de elección toman la forma logística multinomial:
Para identificar el modelo, se normaliza una categoría como base fijando \(\boldsymbol{\beta}_1 = \mathbf{0}\). Los coeficientes del resto de alternativas se interpretan como log-odds relativos a la base:
Un coeficiente positivo de \(x_k\) en la ecuación de la alternativa \(j\) indica que un aumento de \(x_k\) incrementa la probabilidad relativa de elegir \(j\) respecto a la base.
8.3.3 Efectos marginales en el Logit Multinomial
Los coeficientes \(\beta_j\)no representan directamente el cambio en la probabilidad de elegir \(j\). Una variable puede aumentar la probabilidad relativa de \(j\) respecto a la base, pero simultáneamente reducir la probabilidad absoluta de \(j\) si aumenta aún más las de otras alternativas. Los efectos marginales medios (AME) son la medida correcta: promediando sobre la muestra, indican cuánto cambia \(P(y=j)\) ante un cambio unitario en \(x_k\).
8.3.4 La propiedad IIA y sus implicaciones
El Logit Multinomial asume Independencia de Alternativas Irrelevantes (IIA): el ratio de probabilidades entre dos alternativas cualesquiera no depende de la existencia o características de otras alternativas. Formalmente: \(P(y=j)/P(y=k) = \exp[(\boldsymbol{\beta}_j - \boldsymbol{\beta}_k)'\mathbf{x}]\), que no depende de las demás alternativas.
La IIA es restrictiva. El ejemplo clásico es el “problema del autobús rojo/azul”: si un viajero elige entre coche y autobús rojo con probabilidades 1/2 y 1/2, la IIA predice que al añadir un autobús azul (sustituto cercano del rojo), las probabilidades serían 1/3 cada una. Lo razonable sería que el autobús azul robara cuota al rojo (1/2, 1/4, 1/4). El test de Hausman-McFadden permite contrastar la IIA eliminando una alternativa y verificando si los coeficientes cambian.
Cuando la IIA es inaceptable, alternativas son el Probit Multinomial (correlación libre entre alternativas, pero computacionalmente costoso) o el Logit Anidado (nested logit, que agrupa alternativas similares).
8.3.5 Modelos de elección ordenada
Cuando las categorías tienen un orden natural — satisfacción (1-5), calificación crediticia (AAA a D), nivel de acuerdo (totalmente en desacuerdo a totalmente de acuerdo) —, el Logit Multinomial ignora esta información. Los modelos ordenados la aprovechan.
El modelo parte de una variable latente continua no observada:
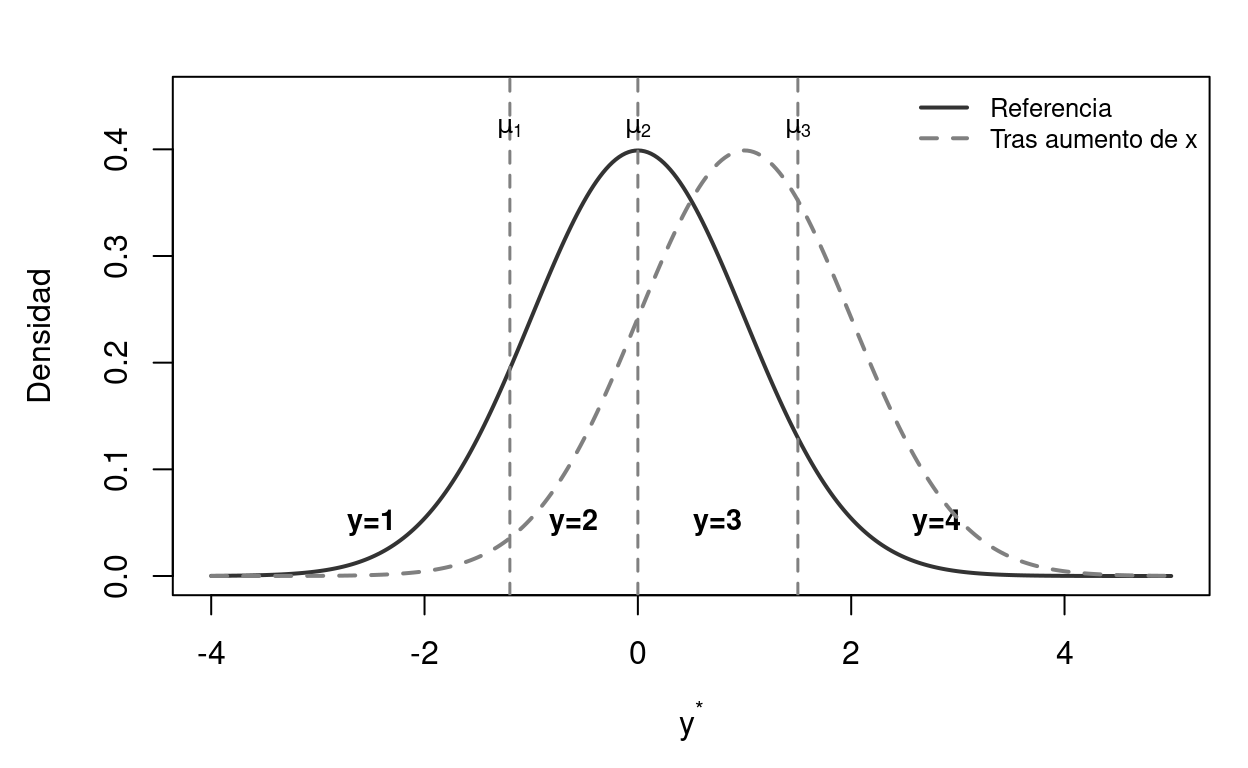
Figure 8.3: Variable latente y umbrales en el modelo ordenado. La distribución se divide en categorías por los umbrales mu. Un cambio en x (línea discontinua) desplaza la distribución, alterando las probabilidades de cada categoría.
Un resultado pedagógicamente importante es que el signo de \(\beta_k\)no determina el signo del efecto marginal en las categorías intermedias. Un aumento de \(x_k\) con \(\beta_k > 0\) siempre reduce \(P(y=1)\) (la categoría más baja) y aumenta \(P(y=J)\) (la más alta), pero su efecto sobre las categorías intermedias puede ser positivo o negativo, dependiendo de dónde se sitúe la densidad respecto a los umbrales.
8.3.6 Bondad del ajuste en modelos cualitativos
Los modelos con variable dependiente cualitativa no tienen un \(R^2\) natural. Las medidas habituales son el Pseudo-\(R^2\) de McFadden (\(1 - \ell_{\text{modelo}}/\ell_{\text{nulo}}\)) y el porcentaje de predicciones correctas (tabla de clasificación). Un modelo que asigna a cada individuo la categoría con mayor probabilidad estimada y acierta el 60% es razonable en muchas aplicaciones — los modelos de elección múltiple rara vez superan el 70-80% de acierto.
8.4 Ejemplo práctico: elección de transporte
Estimamos un Logit Multinomial para la elección entre coche (categoría base), autobús y tren, en función del ingreso, la distancia al trabajo, la edad y la zona de residencia (urbana=1).
Table 8.1: Logit Multinomial para la elección de transporte. Los coeficientes miden log-odds relativos al coche (base). Un coeficiente positivo indica que la variable favorece esa alternativa respecto al coche.
Variable
Bus vs Coche
Tren vs Coche
Intercept
-0.3910
-0.3590
ingreso
-0.0428
-0.0203
distancia
0.1057
0.1708
edad
-0.0069
0.0023
zona_urbana
0.9380
0.5430
Un mayor ingreso reduce la probabilidad de elegir bus o tren respecto al coche (coeficientes negativos) — los individuos con mayores ingresos prefieren el coche. Mayor distancia favorece el tren. Vivir en zona urbana favorece fuertemente el bus (coeficiente 0.94).
Figure 8.4: Distribución de la elección de transporte por zona. En la zona urbana, bus y tren captan más cuota. En la no urbana, el coche domina.
8.5 Casos prácticos
8.5.1 Caso Práctico 1: Elección de transporte
Contexto económico. La elección del medio de transporte es un problema clásico de economía del transporte. Los individuos eligen entre alternativas (coche, autobús, tren) en función de su renta, la distancia al trabajo y la disponibilidad de transporte público en su zona. Comprender estos determinantes es esencial para la planificación de infraestructuras y la política de movilidad urbana.
Datos. Muestra de 1200 individuos que eligen entre tres alternativas: coche (categoría base), autobús y tren. Las covariables son: ingreso (miles de euros anuales), distancia al trabajo (km), edad (años) y zona urbana (1=vive en zona urbana, 0=rural).
Modelo. Logit Multinomial con coche como categoría base. Para cada alternativa (bus, tren) se estima una ecuación de log-odds relativos en función de ingreso, distancia, edad y zona urbana. Se calculan efectos marginales medios y tabla de clasificación.
Objetivo pedagógico. El alumno aprenderá a estimar e interpretar un logit multinomial, calcular AME, evaluar la bondad del ajuste y reflexionar sobre la propiedad IIA.
T08_CP01_mECO_Multinomial_Transporte.R
8.5.2 Caso Práctico 2: Satisfacción laboral
Contexto económico. La satisfacción laboral es un indicador ordinal (de 1=muy insatisfecho a 5=muy satisfecho) que depende de las condiciones de trabajo. Comprender qué factores la determinan permite a las empresas diseñar políticas de retención de talento y a los reguladores evaluar la calidad del empleo.
Datos. Muestra de 1000 trabajadores con satisfacción autodeclarada en 5 niveles. Las covariables son: salario (miles de euros anuales), horas semanales de trabajo, autonomía (escala 1-10 de independencia en el puesto) y antigüedad (años en la empresa).
Modelo. Probit Ordenado con variable latente que depende del salario, horas, autonomía y antigüedad, dividida en 5 categorías por 4 umbrales estimados. Se compara con Logit Ordenado y se calculan efectos marginales por categoría.
Objetivo pedagógico. El alumno comprobará que el signo de \(\beta\) no determina el efecto marginal en categorías intermedias, y aprenderá a comparar Probit y Logit Ordenado.
T08_CP02_mECO_Ordenado_Satisfaccion.R
8.5.3 Caso Práctico 3: Situación laboral
Contexto económico. La situación laboral de un individuo (empleado, desempleado o inactivo) depende de factores demográficos y de capital humano. El número de hijos y el sexo tienen efectos diferenciados: las mujeres con hijos tienen mayor probabilidad de inactividad (no de desempleo), reflejando patrones de participación laboral condicionados por las responsabilidades familiares.
Datos. Muestra de 1500 individuos clasificados en tres situaciones: empleado (base), desempleado e inactivo. Las covariables son: edad (años), educación (años), experiencia laboral (años), número de hijos y sexo (1=mujer).
Modelo. Logit Multinomial con empleado como categoría base. Se espera que la educación y la experiencia reduzcan la probabilidad de desempleo e inactividad, mientras que los hijos y el sexo femenino aumenten especialmente la probabilidad de inactividad.
Objetivo pedagógico. El alumno aprenderá a interpretar coeficientes multinomiales en un contexto de política laboral y a distinguir entre los determinantes del desempleo y los de la inactividad.
T08_CP03_mECO_Multinomial_SitLaboral.R
8.6 Lo esencial del capítulo
Las variables cualitativas como regresores se incorporan mediante variables ficticias (dummies). Con \(K\) categorías se usan \(K-1\) dummies. El coeficiente mide la diferencia respecto a la categoría base. Las interacciones permiten pendientes distintas por grupo. ANOVA solo incluye dummies; ANCOVA añade covariables continuas.
Para variables dependientes cualitativas con múltiples categorías: el Logit Multinomial modela la elección entre alternativas nominales (sin orden) mediante log-odds relativos a una base. La propiedad IIA es su principal limitación. El Probit/Logit Ordenado modela respuestas ordinales mediante una variable latente y umbrales; los efectos marginales en categorías intermedias pueden tener signo contrario al de \(\beta\).
8.7 Funciones esenciales de R
Los scripts completos de este capítulo y los casos prácticos están disponibles en el repositorio del manual:
A continuación se describen las funciones de R más relevantes para el análisis abordado en este capítulo.
8.7.1 factor() y lm() — Variables ficticias y ANOVA/ANCOVA
R crea automáticamente variables ficticias cuando una variable de tipo factor se incluye en una fórmula de regresión. No es necesario crear las dummies manualmente.
datos$sector <-factor(datos$sector)lm(salario ~ sector, data = datos) # ANOVAlm(salario ~ sector + experiencia, data = datos) # ANCOVAlm(salario ~ sector * experiencia, data = datos) # Interacciónanova(modelo) # Tabla ANOVA
Al convertir una variable a factor, R elige la primera categoría (por orden alfabético) como referencia. Para cambiar la categoría base: relevel(datos$sector, ref = "Industria"). El operador * en la fórmula incluye automáticamente el efecto principal y la interacción (equivale a sector + experiencia + sector:experiencia). La función anova() produce la tabla de análisis de la varianza con las sumas de cuadrados, grados de libertad y el estadístico F para cada término.
8.7.2 multinom() — Logit Multinomial
La función multinom() del paquete nnet estima modelos logit multinomiales para variables dependientes nominales con más de dos categorías.
La variable dependiente debe ser un factor con la categoría base como primer nivel. El parámetro trace = FALSE suprime los mensajes de iteración del algoritmo de optimización. El summary() muestra los coeficientes para cada alternativa (una fila por alternativa, excluyendo la base) y sus errores estándar. Para obtener los p-valores, hay que calcularlos manualmente a partir de los estadísticos z: z <- coef(ml)/summary(ml)$standard.errors; p <- 2*(1 - pnorm(abs(z))).
8.7.3 avg_slopes() — Efectos marginales medios
Los coeficientes del logit multinomial no representan directamente cambios en probabilidades. La función avg_slopes() del paquete marginaleffects calcula los efectos marginales medios (AME) correctos.
library(marginaleffects)avg_slopes(ml)
El resultado muestra, para cada variable y cada alternativa, cuánto cambia en promedio la probabilidad de elegir esa alternativa ante un cambio unitario de la variable. A diferencia de los coeficientes brutos, los AME sí tienen interpretación directa en términos de probabilidades.
8.7.4 polr() — Probit y Logit Ordenado
La función polr() del paquete MASS estima modelos de elección ordenada, donde la variable dependiente tiene categorías con orden natural.
La variable dependiente debe ser un factor ordenado: datos$satisf <- factor(datos$satisf, ordered = TRUE). El parámetro method especifica la distribución del error latente: "probit" (normal estándar) o "logistic" (logística). El summary() muestra los coeficientes \(\beta\) (comunes a todas las categorías), sus errores estándar y estadísticos t, y los umbrales estimados \(\hat{\mu}_j\) (llamados Intercepts en el output). Los p-valores no aparecen por defecto; se calculan como 2*pnorm(-abs(coef(summary(oprobit))[,"t value"])).
McFadden, Daniel. 1974. “Conditional Logit Analysis of Qualitative Choice Behavior.”Frontiers in Econometrics, 105–42.