| Empresa | Año | Inversión | Ventas |
|---|---|---|---|
| A | 2021 | 100 | 500 |
| A | 2022 | 110 | 520 |
| A | 2023 | 105 | 510 |
| B | 2021 | 200 | 900 |
| B | 2022 | 210 | 940 |
| B | 2023 | 220 | 980 |
| C | 2021 | 150 | 700 |
| C | 2022 | 140 | 680 |
| C | 2023 | 160 | 720 |
5 Datos de Panel
5.1 De la fotografía a la película
En los capítulos anteriores hemos trabajado con datos de corte transversal: una única observación por individuo en un momento determinado del tiempo. Es como una fotografía: captura el estado de las cosas en un instante, pero no muestra cómo cambian. Este capítulo da un paso fundamental al incorporar la dimensión temporal: los datos de panel contienen observaciones de los mismos \(n\) individuos a lo largo de \(T\) períodos de tiempo. Es la película, no la foto.
Esta estructura aporta ventajas decisivas. La más importante es la capacidad de controlar la heterogeneidad no observada. En muchas aplicaciones económicas, existen características individuales que afectan al comportamiento pero que no podemos medir: la habilidad innata de un trabajador, la cultura organizativa de una empresa, la calidad institucional de un país. Si estas características están correlacionadas con las variables explicativas — y en economía casi siempre lo están —, MCO en corte transversal produce estimaciones sesgadas e inconsistentes. Los datos de panel permiten resolver este problema explotando la variación temporal de cada individuo para separar el efecto de las covariables del efecto de las características permanentes no observadas.
Consideremos un ejemplo concreto. Queremos estimar el efecto de la formación continua sobre el salario. Un trabajador más hábil tiende a formarse más (porque aprende con mayor facilidad) y también gana más (porque es más productivo). Si estimamos la relación salario-formación con datos transversales, el coeficiente de formación capturará tanto el efecto genuino de la formación como el efecto de la habilidad. Este es el clásico sesgo de variable omitida. Con datos de panel, podemos eliminar la habilidad — que es constante en el tiempo — comparando al mismo trabajador consigo mismo en distintos períodos: cuando se formó más versus cuando se formó menos. La diferencia salarial resultante ya no está contaminada por la habilidad, porque esta no ha cambiado.
El modelo que desarrollaremos es:
\[y_{it} = \alpha_i + \mathbf{x}_{it}'\boldsymbol{\beta} + \varepsilon_{it} \tag{5.1}\]
donde \(\alpha_i\) es un efecto individual que captura toda la heterogeneidad no observada que es constante en el tiempo. La pregunta central de este capítulo es cómo tratar \(\alpha_i\): si como un parámetro fijo a estimar (efectos fijos) o como una variable aleatoria no correlacionada con los regresores (efectos aleatorios). Esta elección condiciona toda la inferencia y es, en la práctica, la decisión más importante que debe tomar el investigador cuando trabaja con datos de panel.
5.2 Estructura de los datos de panel
5.2.1 Notación y dimensiones
Un panel tiene dos índices: \(i = 1, \ldots, n\) identifica al individuo (persona, empresa, país, municipio) y \(t = 1, \ldots, T_i\) identifica el período (año, trimestre, mes). El número total de observaciones es \(N = \sum_{i=1}^n T_i\). Cuando todos los individuos se observan el mismo número de períodos, el panel es balanceado (\(T_i = T\) para todo \(i\), y \(N = nT\)); cuando algunos individuos abandonan la muestra o se incorporan más tarde, el panel es no balanceado.
Un panel corto tiene muchos individuos y pocos períodos (\(n\) grande, \(T\) pequeño) — es el caso habitual en microeconometría. Un panel largo tiene la situación inversa (\(T\) grande, \(n\) pequeño) — típico de macroeconometría y finanzas. Esta distinción importa porque las propiedades asintóticas de los estimadores dependen de cuál dimensión crece: en paneles cortos, la consistencia se obtiene cuando \(n \to \infty\) con \(T\) fijo.
5.2.2 Ejemplo numérico
Para fijar ideas, consideremos tres empresas observadas durante tres años. La siguiente tabla muestra la estructura típica de un dataset de panel:
Este panel tiene \(n = 3\) empresas, \(T = 3\) años y \(N = 9\) observaciones. Es balanceado porque las tres empresas aparecen en los tres años.
5.3 La descomposición within/between
Esta descomposición es la idea más importante del análisis de panel, y comprenderla a fondo es esencial para entender por qué los distintos estimadores producen resultados diferentes. Para cualquier variable \(x_{it}\), podemos escribir:
\[x_{it} = \underbrace{\bar{x}_i}_{\text{between}} + \underbrace{(x_{it} - \bar{x}_i)}_{\text{within}}\]
donde \(\bar{x}_i = \frac{1}{T}\sum_{t=1}^T x_{it}\) es la media temporal del individuo \(i\). La variación between mide las diferencias entre las medias de los individuos: ¿invierten más las empresas grandes que las pequeñas? La variación within mide los cambios temporales dentro de cada individuo: ¿ha aumentado la inversión de esta empresa respecto a su propia media?
Para verlo con números, apliquemos la descomposición a los datos de inversión de la tabla anterior:
| Empresa | Año | Inversión | Media empresa | Within |
|---|---|---|---|---|
| A | 2021 | 100 | 105 | -5 |
| A | 2022 | 110 | 105 | 5 |
| A | 2023 | 105 | 105 | 0 |
| B | 2021 | 200 | 210 | -10 |
| B | 2022 | 210 | 210 | 0 |
| B | 2023 | 220 | 210 | 10 |
| C | 2021 | 150 | 150 | 0 |
| C | 2022 | 140 | 150 | -10 |
| C | 2023 | 160 | 150 | 10 |
La variación between se lee en la columna \(\bar{y}_i\): las medias son 105, 210 y 150 — la empresa B invierte el doble que la A. La variación within se lee en la última columna: dentro de cada empresa, las desviaciones son pequeñas (\(\pm 5\), \(\pm 10\)). En este ejemplo, la variación between domina claramente sobre la within, lo que es habitual cuando los individuos son muy heterogéneos.
Veamos esta descomposición gráficamente. El siguiente gráfico muestra la inversión de las tres empresas a lo largo del tiempo. La distancia vertical entre las líneas discontinuas horizontales (medias de cada empresa) representa la variación between; las oscilaciones de cada línea alrededor de su media representan la variación within.
Code
par(mar = c(4, 4.5, 2, 1))
plot(NA, xlim = c(0.8, 3.2), ylim = c(80, 240),
xlab = "Año", ylab = "Inversión (miles EUR)",
main = "Variación within vs between", xaxt = "n")
axis(1, at = 1:3, labels = 2021:2023)
medias <- c(105, 210, 150)
ingresos <- list(c(100, 110, 105), c(200, 210, 220), c(150, 140, 160))
ltys_ej <- c(1, 2, 4)
pchs_ej <- c(16, 1, 17)
for (i in 1:3) {
lines(1:3, ingresos[[i]], type = "b", pch = pchs_ej[i], lty = ltys_ej[i],
col = gray(0.2), lwd = 2)
abline(h = medias[i], col = gray(0.5), lty = 3, lwd = 1)
}
legend("topleft", c("Empresa A (media=105)", "Empresa B (media=210)",
"Empresa C (media=150)"),
lty = ltys_ej, pch = pchs_ej, col = gray(0.2), lwd = 2,
cex = 0.8, bty = "n")
# Anotación between
arrows(3.15, medias[1], 3.15, medias[3], code = 3, col = gray(0.4),
lwd = 1.5, length = 0.06)
text(3.25, mean(c(medias[1], medias[3])), "between", cex = 0.7,
col = gray(0.3), srt = 90)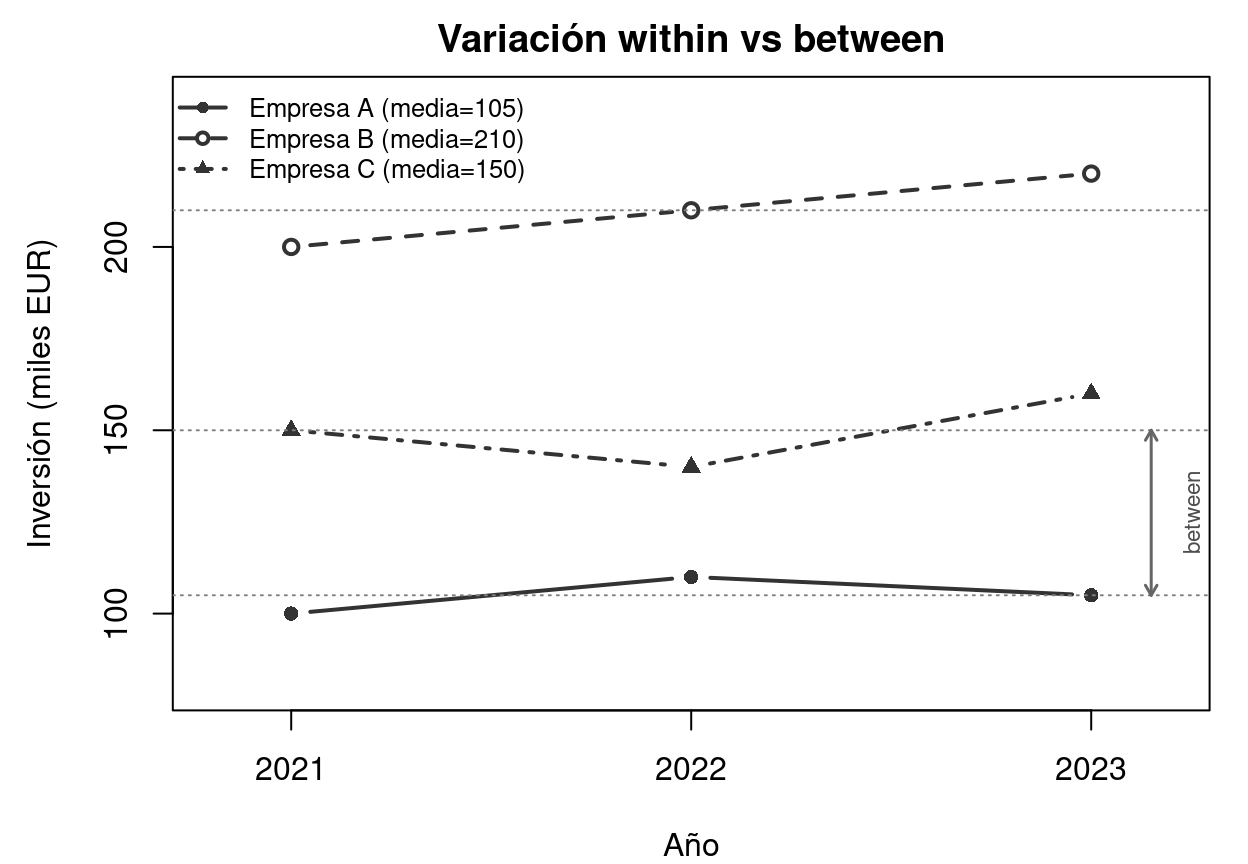
Esta descomposición tiene implicaciones directas para la estimación. El estimador de efectos fijos utiliza exclusivamente la variación within: compara a cada individuo consigo mismo a lo largo del tiempo. El estimador between utiliza solo las medias individuales. El de efectos aleatorios combina ambas fuentes de variación de forma ponderada. La elección del estimador es, en esencia, una decisión sobre qué tipo de variación queremos explotar.
5.4 El modelo general y las tres estrategias
5.4.1 Especificación del modelo
El modelo de panel más general tiene la forma:
\[y_{it} = \alpha_i + \mathbf{x}_{it}'\boldsymbol{\beta} + \varepsilon_{it}, \qquad i = 1, \ldots, n; \quad t = 1, \ldots, T \tag{5.2}\]
donde \(y_{it}\) es la variable dependiente del individuo \(i\) en el período \(t\), \(\mathbf{x}_{it}\) es un vector \(k \times 1\) de covariables observadas, \(\boldsymbol{\beta}\) es el vector de parámetros de interés (común a todos los individuos), \(\alpha_i\) es el efecto individual no observado (constante en el tiempo), y \(\varepsilon_{it}\) es el error idiosincrásico (varía entre individuos y períodos).
El efecto individual \(\alpha_i\) captura todo lo que es constante en el tiempo y no está incluido en \(\mathbf{x}_{it}\): la habilidad innata de un trabajador, la localización geográfica de una empresa, la calidad institucional de un país, la cultura organizativa. La pregunta central del análisis de panel es si \(\alpha_i\) está correlacionado con \(\mathbf{x}_{it}\) o no. Esta pregunta no es técnica — es sustantiva y depende del problema económico que se estudia.
Los supuestos básicos del modelo son:
\[E[\varepsilon_{it} \mid \mathbf{x}_{i1}, \ldots, \mathbf{x}_{iT}, \alpha_i] = 0 \quad \text{(exogeneidad estricta)}\]
\[E[\varepsilon_{it}^2 \mid \mathbf{x}_{i1}, \ldots, \mathbf{x}_{iT}, \alpha_i] = \sigma_\varepsilon^2 \quad \text{(homocedasticidad)}\]
\[E[\varepsilon_{it}\varepsilon_{is} \mid \mathbf{x}_{i1}, \ldots, \mathbf{x}_{iT}, \alpha_i] = 0 \quad \text{para } t \neq s \quad \text{(no autocorrelación)}\]
El supuesto de exogeneidad estricta es fuerte: exige que el error en \(t\) no esté correlacionado con los regresores de ningún período, pasado, presente o futuro. Esto excluye modelos con retroalimentación (feedback) y con la variable dependiente retardada como regresor.
5.4.2 Pooled OLS: ignorar la estructura de panel
El enfoque más simple trata todas las \(nT\) observaciones como un único corte transversal, ignorando que proceden de los mismos individuos observados repetidamente:
\[y_{it} = \alpha + \mathbf{x}_{it}'\boldsymbol{\beta} + u_{it}, \qquad u_{it} = \alpha_i - \alpha + \varepsilon_{it}\]
El error compuesto \(u_{it}\) contiene el efecto individual \(\alpha_i\), que introduce dos problemas. El primero: si \(\text{Cov}(\alpha_i, \mathbf{x}_{it}) \neq 0\), el estimador es inconsistente por variable omitida — los coeficientes estimados están sesgados. El segundo: incluso si \(\alpha_i\) es independiente de \(\mathbf{x}_{it}\), los errores están autocorrelacionados dentro de cada individuo (\(\text{Cov}(u_{it}, u_{is}) = \sigma_\alpha^2 \neq 0\) para \(t \neq s\)), de modo que los errores estándar clásicos son incorrectos. Si se usa Pooled OLS, es imprescindible reportar siempre errores clustered por individuo.
5.5 Efectos Fijos: el estimador within
5.5.1 La transformación within
Si \(\alpha_i\) contamina la estimación porque está correlacionado con los regresores, la solución más directa es eliminarlo. Para ello, calculamos la media temporal de la Equation 5.2 para cada individuo:
\[\bar{y}_i = \alpha_i + \bar{\mathbf{x}}_i'\boldsymbol{\beta} + \bar{\varepsilon}_i\]
y restamos esta media de cada observación:
\[(y_{it} - \bar{y}_i) = (\mathbf{x}_{it} - \bar{\mathbf{x}}_i)'\boldsymbol{\beta} + (\varepsilon_{it} - \bar{\varepsilon}_i)\]
El efecto \(\alpha_i\) ha desaparecido porque \(\alpha_i - \alpha_i = 0\). Definiendo \(\tilde{y}_{it} = y_{it} - \bar{y}_i\) y \(\tilde{\mathbf{x}}_{it} = \mathbf{x}_{it} - \bar{\mathbf{x}}_i\), el modelo transformado es:
\[\tilde{y}_{it} = \tilde{\mathbf{x}}_{it}'\boldsymbol{\beta} + \tilde{\varepsilon}_{it} \tag{5.3}\]
Esta es la transformación within o de desviaciones respecto a la media. Aplicar MCO a la Equation 5.3 produce el estimador de efectos fijos (o estimador within):
\[\hat{\boldsymbol{\beta}}_{EF} = \left(\sum_{i=1}^n \sum_{t=1}^T \tilde{\mathbf{x}}_{it}\tilde{\mathbf{x}}_{it}'\right)^{-1} \left(\sum_{i=1}^n \sum_{t=1}^T \tilde{\mathbf{x}}_{it}\tilde{y}_{it}\right) \tag{5.4}\]
5.5.2 Ejemplo numérico paso a paso
Veamos cómo funciona la transformación within con un ejemplo mínimo: dos individuos y tres períodos.
| i | t | y | x | Media y | Media x | Within y | Within x |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 10 | 2 | 12 | 3 | -2 | -1 |
| 1 | 2 | 12 | 3 | 12 | 3 | 0 | 0 |
| 1 | 3 | 14 | 4 | 12 | 3 | 2 | 1 |
| 2 | 1 | 20 | 5 | 22 | 6 | -2 | -1 |
| 2 | 2 | 22 | 6 | 22 | 6 | 0 | 0 |
| 2 | 3 | 24 | 7 | 22 | 6 | 2 | 1 |
El cálculo del estimador es inmediato:
\[\hat{\beta}_{EF} = \frac{\sum \tilde{x}_{it}\tilde{y}_{it}}{\sum \tilde{x}_{it}^2} = \frac{2+0+2+2+0+2}{1+0+1+1+0+1} = \frac{8}{4} = 2\]
Los efectos individuales \(\alpha_1\) y \(\alpha_2\) — que podrían ser 0 y 10, o cualquier par de valores que generen las medias observadas — han desaparecido completamente del cálculo. El estimador within identifica \(\beta\) exclusivamente a partir de la variación temporal dentro de cada individuo.
5.5.3 Propiedades del estimador de efectos fijos
El estimador de efectos fijos es consistente independientemente de que \(\alpha_i\) esté correlacionado con \(\mathbf{x}_{it}\) o no, siempre que se cumpla el supuesto de exogeneidad estricta. Esta robustez es su gran fortaleza y la razón por la que es la opción por defecto en microeconometría aplicada. Sin embargo, tiene dos limitaciones importantes que el investigador debe conocer.
La primera limitación es que no puede estimar el efecto de variables que no varían en el tiempo (sexo, raza, región, sector). La transformación within las elimina junto con \(\alpha_i\), porque \(\tilde{x}_{it} = x_{it} - \bar{x}_i = 0\) cuando \(x_{it}\) es constante. Si el investigador necesita estimar estos efectos, debe recurrir a efectos aleatorios o a enfoques como Mundlak (1978) o Hausman-Taylor.
La segunda limitación es que el estimador within es menos eficiente que el de efectos aleatorios cuando \(\alpha_i\) no está correlacionado con los regresores. Al descartar toda la variación between, el within utiliza solo una parte de la información disponible.
5.5.4 Grados de libertad
Los grados de libertad del estimador within son \(nT - n - k\), no \(nT - k - 1\). Los \(n\) grados adicionales se pierden al estimar (implícitamente) los \(n\) efectos individuales. En paneles cortos con \(T\) pequeño, esto puede reducir significativamente la potencia de los contrastes.
5.6 Primeras diferencias
Una alternativa a la transformación within es restar la observación del período anterior en lugar de la media:
\[\Delta y_{it} = y_{it} - y_{i,t-1} = \Delta \mathbf{x}_{it}'\boldsymbol{\beta} + \Delta \varepsilon_{it} \tag{5.5}\]
donde \(\Delta\) denota el operador de primeras diferencias. Al igual que el within, esta transformación elimina \(\alpha_i\) porque \(\alpha_i - \alpha_i = 0\). Las dos transformaciones son equivalentes cuando \(T = 2\): con solo dos períodos, la desviación respecto a la media es exactamente la mitad de la primera diferencia.
Con \(T > 2\), los dos estimadores son generalmente diferentes. Si los errores \(\varepsilon_{it}\) son iid (independientes e idénticamente distribuidos), el estimador within es más eficiente porque utiliza toda la variación within. Pero si los errores siguen un paseo aleatorio (\(\varepsilon_{it} = \varepsilon_{i,t-1} + \eta_{it}\)), las primeras diferencias son preferibles porque \(\Delta \varepsilon_{it} = \eta_{it}\) es iid, mientras que los errores within estarían fuertemente autocorrelacionados. En la práctica, cuando los estimadores within y FD difieren sustancialmente, es señal de que algún supuesto del modelo — típicamente la exogeneidad estricta — puede estar violado.
5.7 Efectos Aleatorios: el estimador GLS
5.7.1 El supuesto clave
Si \(\alpha_i\) no está correlacionado con \(\mathbf{x}_{it}\), existe un estimador más eficiente que el within: el de efectos aleatorios (EA). Este estimador trata \(\alpha_i\) como una variable aleatoria con:
\[E[\alpha_i] = 0, \qquad \text{Var}(\alpha_i) = \sigma_\alpha^2, \qquad \text{Cov}(\alpha_i, \mathbf{x}_{it}) = 0\]
Bajo estos supuestos, el error compuesto \(u_{it} = \alpha_i + \varepsilon_{it}\) tiene una estructura de covarianza conocida:
\[\text{Var}(u_{it}) = \sigma_\alpha^2 + \sigma_\varepsilon^2, \qquad \text{Cov}(u_{it}, u_{is}) = \sigma_\alpha^2 \quad (t \neq s)\]
Esta estructura permite aplicar Mínimos Cuadrados Generalizados (GLS), que es MCO sobre datos transformados con el factor:
\[\theta = 1 - \sqrt{\frac{\sigma_\varepsilon^2}{\sigma_\varepsilon^2 + T\sigma_\alpha^2}} \tag{5.6}\]
5.7.2 La transformación cuasi-within
La transformación GLS resta una fracción \(\theta\) de la media individual:
\[y_{it} - \theta\bar{y}_i = (1-\theta)\alpha + (\mathbf{x}_{it} - \theta\bar{\mathbf{x}}_i)'\boldsymbol{\beta} + (u_{it} - \theta\bar{u}_i)\]
Cuando \(\sigma_\alpha^2\) es grande (mucha heterogeneidad no observada), \(\theta \to 1\) y EA converge a efectos fijos: se resta la media completa. Cuando \(\sigma_\alpha^2\) es pequeña (poca heterogeneidad), \(\theta \to 0\) y EA converge a Pooled OLS: no se resta nada. El estimador de efectos aleatorios es, por tanto, un promedio ponderado entre Pooled OLS y efectos fijos, donde el peso depende de la importancia relativa de la heterogeneidad no observada.
La gran ventaja de EA es que puede estimar el efecto de variables invariantes en el tiempo (sexo, región, sector), ya que la transformación cuasi-within no las elimina completamente. Su riesgo es igualmente claro: si el supuesto de no correlación entre \(\alpha_i\) y \(\mathbf{x}_{it}\) es falso, el estimador es inconsistente. Usarlo cuando no corresponde produce estimaciones sesgadas — un error más grave que la pérdida de eficiencia de usar EF cuando EA sería correcto.
Code
par(mar=c(4.5, 4.5, 2, 1))
ratio <- seq(0, 10, length.out=200)
TT <- c(3, 5, 10, 20)
ltys_th <- c(1,2,3,4)
plot(NA, xlim=c(0,10), ylim=c(0,1),
xlab=expression(sigma[alpha]^2 / sigma[epsilon]^2),
ylab=expression(theta), main="")
for (j in seq_along(TT)) {
theta_vals <- 1 - sqrt(1 / (1 + TT[j]*ratio))
lines(ratio, theta_vals, lty=ltys_th[j], lwd=2, col=gray(0.1+0.15*j))
}
abline(h=c(0,1), lty=3, col=gray(0.6))
legend("bottomright",
paste0("T = ", TT), lty=ltys_th, lwd=2,
col=gray(0.1+0.15*seq_along(TT)), cex=0.8, bty="n")
text(0.3, 0.05, "Pooled OLS", cex=0.7, font=3)
text(8, 0.95, "Efectos Fijos", cex=0.7, font=3)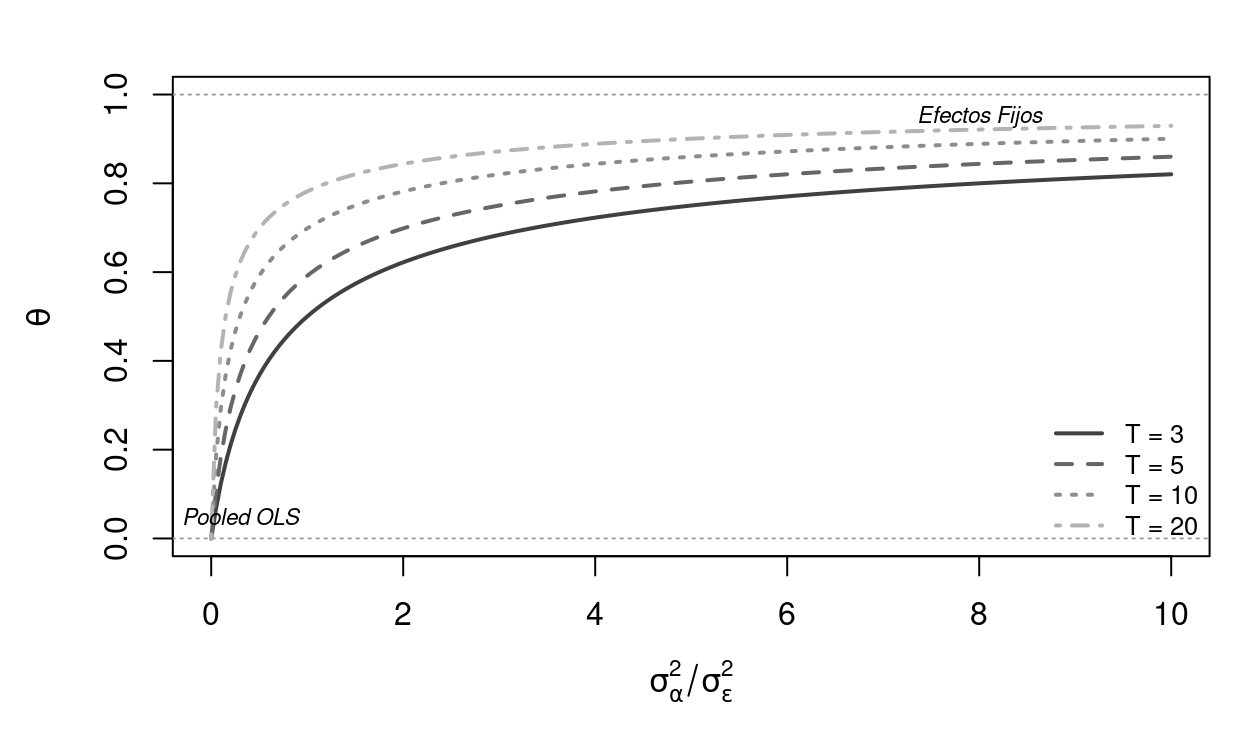
Regla práctica: Cuando hay duda sobre si \(\alpha_i\) correlaciona con los regresores, usar efectos fijos. Es la opción conservadora: siempre es consistente. Solo usar EA si el test de Hausman lo avala y se necesita estimar variables invariantes en el tiempo.
5.8 El test de Hausman
5.8.1 Formulación
El test de Hausman (1978) compara formalmente los estimadores de EF y EA. La lógica es elegante: bajo \(H_0\) (EA es correcto), ambos estimadores son consistentes, pero EA es más eficiente. Bajo \(H_1\) (EA es incorrecto porque \(\alpha_i\) correlaciona con \(\mathbf{x}_{it}\)), solo EF es consistente. Si los dos estimadores difieren significativamente, la diferencia se debe a la inconsistencia de EA.
El estadístico es:
\[H = (\hat{\boldsymbol{\beta}}_{EF} - \hat{\boldsymbol{\beta}}_{EA})'\left[\widehat{\text{Var}}(\hat{\boldsymbol{\beta}}_{EF}) - \widehat{\text{Var}}(\hat{\boldsymbol{\beta}}_{EA})\right]^{-1}(\hat{\boldsymbol{\beta}}_{EF} - \hat{\boldsymbol{\beta}}_{EA}) \sim \chi^2_k \tag{5.7}\]
donde \(k\) es el número de regresores (excluyendo variables invariantes en el tiempo, que solo EA estima).
5.8.2 Regla de decisión
Si \(p < 0.05\): se rechaza \(H_0\) — los estimadores difieren significativamente. Usar efectos fijos. Si \(p > 0.05\): no se rechaza \(H_0\) — EA es adecuado y más eficiente. Usar efectos aleatorios.
En la práctica, el test de Hausman tiende a rechazar EA en muestras grandes, incluso cuando la diferencia entre estimadores es económicamente irrelevante. Una alternativa es comparar los coeficientes sustantivamente: si los coeficientes de EF y EA son prácticamente iguales, EA es razonable con independencia del p-valor formal.
5.9 Batería de diagnósticos
5.9.1 Test F de efectos individuales
Antes de elegir entre EF y EA, conviene verificar que realmente existen efectos individuales. El test F contrasta:
\[H_0: \alpha_1 = \alpha_2 = \cdots = \alpha_n \qquad \text{(Pooled OLS es suficiente)}\]
Si se rechaza \(H_0\), los individuos son significativamente heterogéneos y Pooled OLS es inadecuado. En R: pFtest(modelo_fe, modelo_pooled).
5.9.2 Test LM de Breusch-Pagan
Alternativa al F-test que contrasta \(H_0: \sigma_\alpha^2 = 0\) (no hay varianza individual). Si se rechaza, hay heterogeneidad no observada. En R: plmtest(modelo_pooled, type="bp").
5.9.3 Test de Wooldridge para autocorrelación serial
El supuesto de no autocorrelación en \(\varepsilon_{it}\) es importante porque, si falla, los errores estándar del estimador within son incorrectos. El test de Wooldridge contrasta \(H_0:\) no hay autocorrelación AR(1). En R: pwartest(modelo_fe).
5.9.4 Errores robustos (clustered)
La recomendación estándar en la literatura aplicada es reportar siempre errores estándar robustos clustered por individuo, independientemente de los resultados de los diagnósticos anteriores. Estos errores corrigen simultáneamente por heterocedasticidad y autocorrelación serial de forma no restringida. En R:
coeftest(modelo, vcov = vcovHC(modelo, type="HC1", cluster="group"))
5.10 Ejemplo práctico: datos de Grunfeld
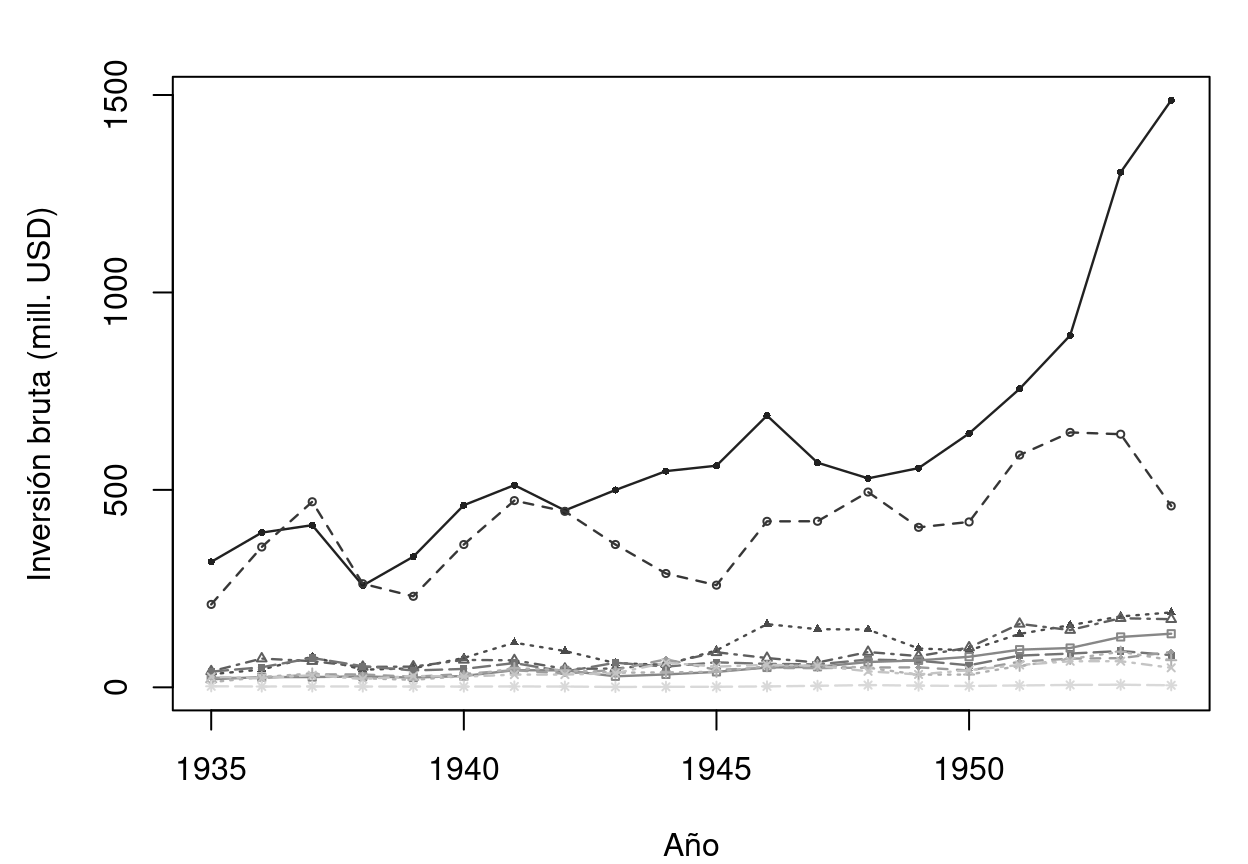
Ilustramos todo el procedimiento con el dataset clásico de Grunfeld (1958): inversión bruta de 10 empresas estadounidenses durante 20 años (1935-1954), con el valor de mercado y el stock de capital como covariables.
| Variable | Media | D.E. | Mín. | Máx. |
|---|---|---|---|---|
| inv (inversión) | 146.0 | 216.9 | 0.9 | 1486.7 |
| value (valor mercado) | 1081.7 | 1314.5 | 58.1 | 6241.7 |
| capital (stock capital) | 276.0 | 301.1 | 0.8 | 2226.3 |
El gráfico siguiente muestra la evolución de la inversión de cada empresa. La enorme variación between (empresas grandes vs pequeñas) es visible a simple vista, mientras que la variación within (oscilaciones temporales de cada empresa) es más sutil.
Code
par(mar=c(4, 4.5, 2, 1))
firmas <- unique(Grunfeld$firm)
ltys_g <- rep(1:5, 2)
pchs_g <- c(16,1,17,2,15,0,18,3,4,8)
plot(NA, xlim=range(Grunfeld$year), ylim=range(Grunfeld$inv),
xlab="Año", ylab="Inversión bruta (mill. USD)")
for (i in seq_along(firmas)) {
sub <- Grunfeld[Grunfeld$firm==firmas[i],]
lines(sub$year, sub$inv, lty=ltys_g[i], col=gray(0.05+0.08*i), lwd=1.2)
points(sub$year, sub$inv, pch=pchs_g[i], col=gray(0.05+0.08*i), cex=0.5)
}
5.10.1 Estimación comparativa
Estimamos los tres modelos — Pooled OLS, Efectos Fijos y Efectos Aleatorios — con la misma especificación: inversión en función del valor de mercado y el stock de capital.
| Variable | Pooled OLS | Efectos Fijos | Efectos Aleatorios |
|---|---|---|---|
| value | 0.1156 (0.0058) | 0.1101 (0.0119) | 0.1098 (0.0105) |
| capital | 0.2307 (0.0255) | 0.3101 (0.0174) | 0.3081 (0.0172) |
| Nota: | |||
| Errores estándar entre paréntesis. |
Los coeficientes de los tres estimadores son cualitativamente similares: tanto el valor de mercado como el stock de capital tienen efectos positivos y significativos sobre la inversión. Sin embargo, las magnitudes difieren. Para determinar cuál estimador es el apropiado, procedemos con los tests de diagnóstico.
5.10.2 Tests de especificación
El test F de efectos individuales arroja \(F =\) 49.18 con p-valor \(<\) 0.001, lo que confirma que los efectos individuales son altamente significativos: las 10 empresas tienen niveles base de inversión muy diferentes, y Pooled OLS no es adecuado.
El test LM de Breusch-Pagan arroja \(\chi^2 =\) 798.16 con p-valor \(<\) 0.001, confirmando la existencia de heterogeneidad individual.
El test de Hausman arroja \(H =\) 2.33 con p-valor \(=\) 0.3119. No se rechaza \(H_0\): el estimador de efectos aleatorios es adecuado.
5.10.3 Efectos fijos individuales
El siguiente gráfico muestra los efectos fijos estimados para cada empresa. La dispersión refleja la enorme heterogeneidad en el nivel base de inversión: las empresas grandes (General Motors, US Steel) tienen interceptos mucho más altos que las pequeñas.
Code
ef <- fixef(mod_fe)
par(mar = c(6, 5, 2, 1))
bp <- barplot(sort(ef),
col = gray(seq(0.3, 0.8, length.out = length(ef))),
border = "white", las = 2, ylab = "Efecto fijo estimado",
cex.names = 0.7)
abline(h = 0, col = gray(0.4), lty = 2, lwd = 1.5)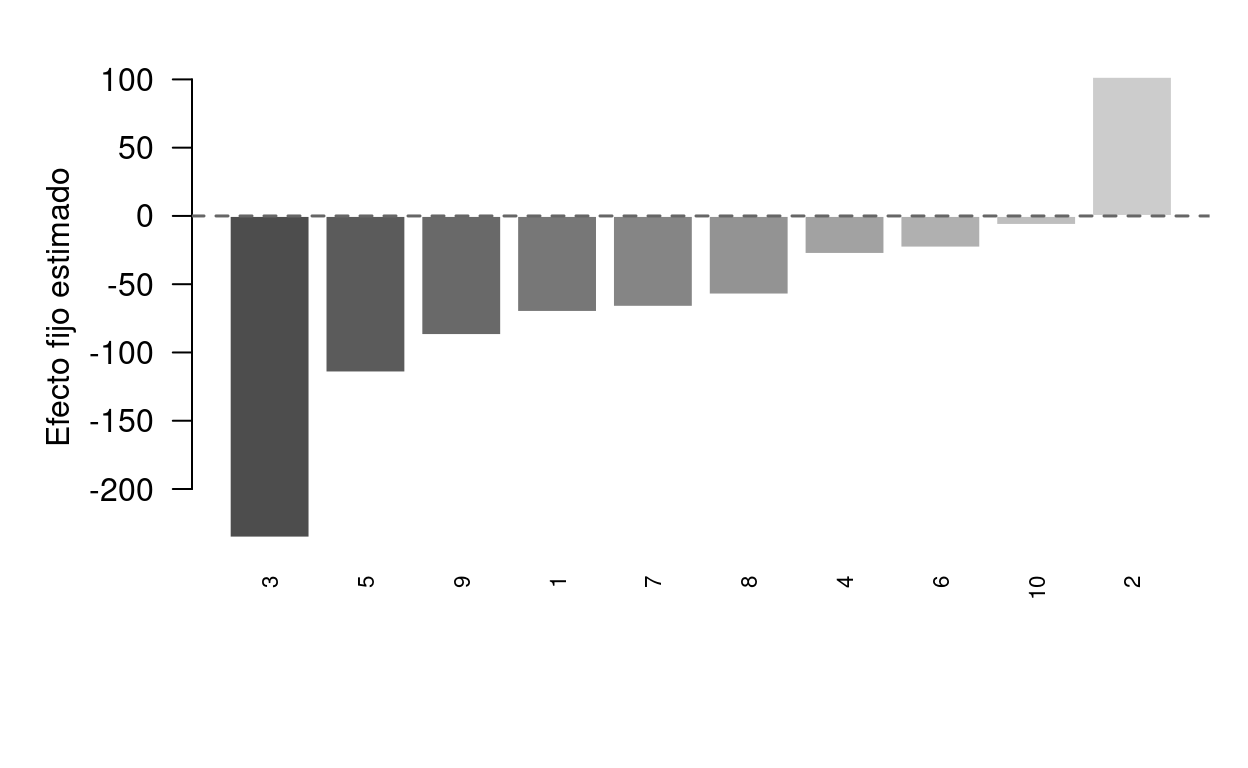
5.10.4 Comparación visual: Pooled OLS vs Efectos Fijos
La diferencia entre Pooled OLS y EF se aprecia claramente cuando representamos las rectas de regresión. Pooled OLS ajusta una única recta para toda la muestra, mezclando la variación between (diferencias de nivel entre empresas) con la within (cambios temporales). EF ajusta rectas paralelas — misma pendiente pero distinto intercepto — para cada empresa.
Code
par(mfrow=c(1,2), mar=c(4.5,4.5,2.5,0.5), cex.main=0.88)
plot(Grunfeld$value, Grunfeld$inv, pch=1, col=gray(0.6), cex=0.6,
xlab="Valor de mercado", ylab="Inversión", main="Pooled OLS")
abline(coef(mod_pooled)[1], coef(mod_pooled)["value"], lwd=2, lty=1)
plot(Grunfeld$value, Grunfeld$inv, pch=1, col=gray(0.6), cex=0.6,
xlab="Valor de mercado", ylab="Inversión", main="Efectos Fijos")
ltys_ef <- rep(1:5, 2)
for (i in seq_along(firmas)) {
abline(ef[i], coef(mod_fe)["value"], lty=ltys_ef[i],
col=gray(0.2+0.05*i), lwd=0.7)
}
par(mfrow=c(1,1))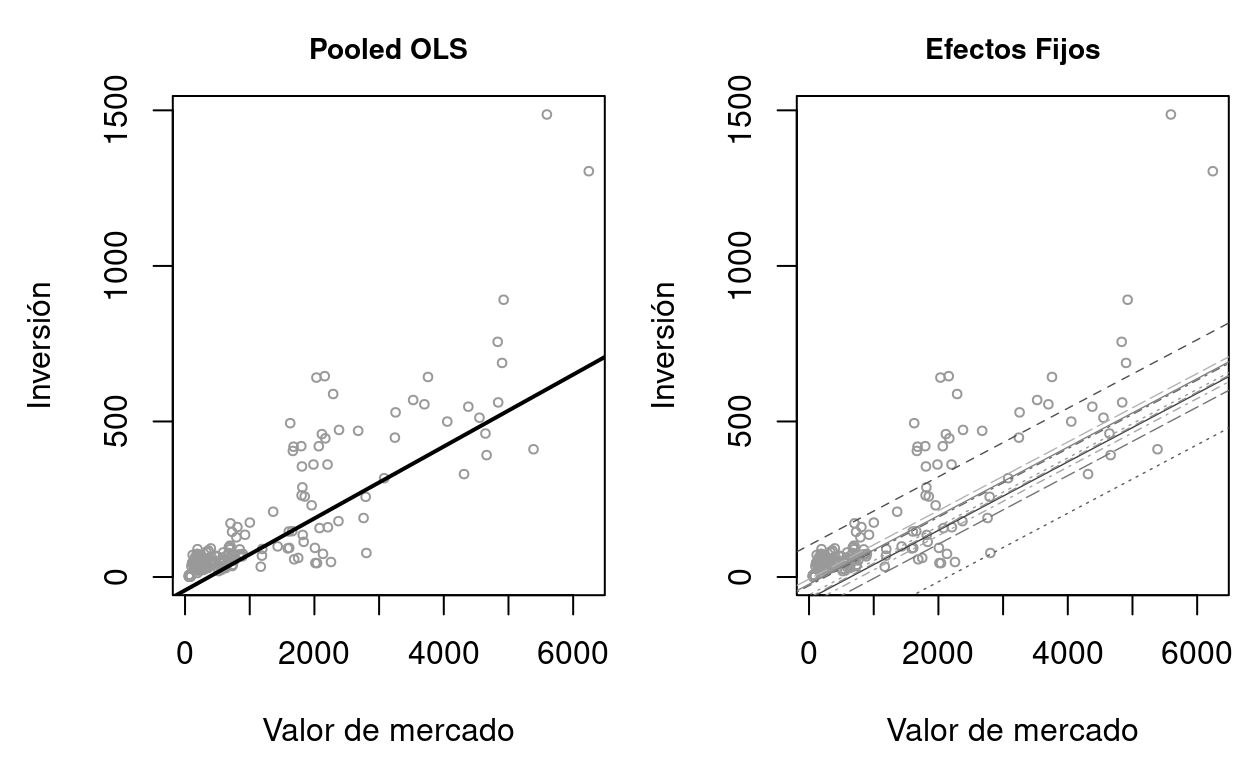
5.11 Extensiones
5.11.1 Efectos fijos bidireccionales
En muchas aplicaciones, además de los efectos individuales \(\alpha_i\), existen perturbaciones que afectan a todos los individuos en un período determinado: una crisis financiera, un cambio legislativo, una pandemia. Estos efectos temporales se capturan añadiendo dummies de período:
\[y_{it} = \alpha_i + \lambda_t + \mathbf{x}_{it}'\boldsymbol{\beta} + \varepsilon_{it}\]
Los \(\lambda_t\) absorben cualquier shock común a todos los individuos en el período \(t\). En R: plm(..., effect = "twoways"). Es recomendable incluir efectos temporales como práctica estándar, especialmente en paneles que cubren períodos de inestabilidad económica.
5.11.2 Diferencias en Diferencias (DiD)
La estrategia de Diferencias en Diferencias es una extensión natural del modelo de panel que permite estimar efectos causales de una intervención o tratamiento. El modelo es:
\[y_{it} = \alpha + \gamma \cdot \text{tratado}_i + \delta \cdot \text{post}_t + \tau \cdot (\text{tratado}_i \times \text{post}_t) + \varepsilon_{it}\]
El coeficiente \(\tau\) estima el efecto causal del tratamiento, bajo el supuesto de tendencias paralelas: en ausencia del tratamiento, el grupo tratado y el de control habrían seguido trayectorias paralelas. Este supuesto no es testable directamente, pero puede evaluarse inspeccionando las tendencias pre-tratamiento.
5.11.3 Paneles dinámicos
Cuando la variable dependiente retardada \(y_{i,t-1}\) aparece como regresor, el estimador within es sesgado en paneles cortos. Esto se conoce como el sesgo de Nickell (1981): la transformación within genera correlación mecánica entre el regresor transformado \((\tilde{y}_{i,t-1})\) y el error transformado \((\tilde{\varepsilon}_{it})\). La solución estándar es el estimador de Arellano-Bond (1991), que utiliza retardos de la variable dependiente como instrumentos en un marco GMM. En R: pgmm() del paquete plm.
5.12 Esquema de decisión
La siguiente secuencia guía la elección del estimador:
Paso 1. ¿Tienes datos de los mismos individuos en varios períodos? Si sí, estás en panel. Si no, usa modelos de corte transversal (capítulos 1-4).
Paso 2. ¿Hay heterogeneidad individual? Aplica el test F (pFtest) o Breusch-Pagan (plmtest). Si se rechaza \(H_0\), Pooled OLS no es adecuado.
Paso 3. ¿Está \(\alpha_i\) correlacionado con \(\mathbf{x}_{it}\)? Aplica el test de Hausman (phtest). Si \(p < 0.05\) \(\to\) Efectos Fijos. Si \(p > 0.05\) \(\to\) Efectos Aleatorios.
Paso 4. ¿Necesitas estimar variables invariantes en el tiempo? Solo EA puede hacerlo directamente. Si Hausman rechaza EA pero necesitas estas variables, considera Mundlak (1978) o Hausman-Taylor.
Paso 5. ¿Tu variable dependiente retardada es regresor? \(\to\) Panel dinámico. Usa Arellano-Bond, no EF.
Paso 6. Reporta siempre errores clustered por individuo.
5.13 Casos prácticos
5.13.1 Caso Práctico 1: Inversión empresarial
Contexto económico. La teoría de la inversión establece que las empresas invierten en función de las oportunidades de crecimiento (aproximadas por las ventas) y del stock de capital existente, con la deuda actuando como restricción financiera. Un aspecto clave es que cada empresa tiene características permanentes no observadas (calidad de la gestión, cultura corporativa, localización) que afectan tanto a su nivel de inversión como a sus ventas, generando potencial endogeneidad.
Datos. Panel de 80 empresas españolas observadas durante 10 años (2011-2020), con 800 observaciones. La variable dependiente es la inversión bruta (miles de euros). Los regresores son: ventas (facturación anual), stock de capital (valor de planta y equipo), deuda (pasivo financiero) y sector (Industria, Servicios, Tecnología o Construcción — invariante en el tiempo).
Modelo. Se estima el modelo de inversión en función de ventas, capital y deuda con efectos fijos individuales. Los datos están simulados con efectos fijos correlacionados con el tamaño de la empresa, de modo que Pooled OLS y EA producen estimaciones sesgadas. El test de Hausman deberá indicar que EF es el estimador correcto.
Objetivo pedagógico. El alumno aprenderá a estimar los tres modelos (Pooled, EF, EA), realizar la batería completa de diagnósticos (F-test, Hausman, Wooldridge), interpretar los efectos fijos individuales y reportar resultados con errores clustered.
T05_CP01_mECO_Panel_Inversion.R
5.13.2 Caso Práctico 2: Desempleo regional
Contexto económico. La tasa de desempleo de una región depende de factores económicos que varían en el tiempo (PIB per cápita, gasto en educación) y de características estructurales permanentes (situación geográfica, tejido productivo). Nos interesa estimar el efecto de las políticas de gasto educativo sobre el desempleo, controlando por la heterogeneidad regional no observada.
Datos. Panel de 50 provincias españolas durante 15 años (2006-2020), con 750 observaciones. La variable dependiente es la tasa de desempleo (%). Los regresores son: PIB per cápita (miles de euros), gasto en educación (% del PIB provincial), población activa (miles) y costa (dummy: 1 si la provincia tiene litoral, invariante en el tiempo).
Modelo. Se estima el modelo con Pooled, EF y EA. El elemento clave es la variable costa: al ser invariante en el tiempo, EF la elimina. Solo EA puede estimar su efecto. El caso ilustra la tensión entre consistencia (EF) y la capacidad de estimar variables invariantes (EA). También se estiman efectos fijos bidireccionales para capturar shocks macroeconómicos comunes.
Objetivo pedagógico. El alumno comprenderá por qué EF no puede estimar el efecto de variables constantes, cuándo EA es preferible, y cómo los efectos temporales capturan perturbaciones comunes (crisis de 2008-2013).
T05_CP02_mECO_Panel_Desempleo.R
5.13.3 Caso Práctico 3: Salarios y formación
Contexto económico. Estimar el retorno salarial de la formación continua es un problema clásico de econometría laboral. La habilidad innata del trabajador (no observada) correlaciona positivamente con las horas de formación (los más hábiles se forman más) y con el salario (son más productivos). Este sesgo de variable omitida hace que Pooled OLS sobreestime el retorno de la formación.
Datos. Panel de 500 trabajadores durante 5 años (2016-2020), con 2500 observaciones. La variable dependiente es log(salario). Los regresores son: experiencia (años), horas de formación (anuales), antigüedad (años en la empresa) y sexo (1=mujer, invariante en el tiempo). La habilidad no observada está incorporada en los datos como efecto fijo correlacionado con la formación.
Modelo. Se estima el logaritmo del salario en función de la experiencia, las horas de formación y la antigüedad, con efectos fijos individuales. La comparación clave es entre el coeficiente de formación en Pooled OLS (sesgado al alza) y en EF (corregido). También se compara con primeras diferencias y se muestra que el sexo solo es estimable con EA.
Objetivo pedagógico. El alumno aprenderá a diagnosticar y cuantificar el sesgo de variable omitida, entender por qué EF lo corrige, y valorar el trade-off entre consistencia y capacidad de estimar variables invariantes.
T05_CP03_mECO_Panel_Salarios.R
5.14 Lo esencial del capítulo
Los datos de panel observan a los mismos individuos a lo largo del tiempo, permitiendo controlar la heterogeneidad no observada que contamina las estimaciones de corte transversal. La variación de los datos se descompone en within (cambios temporales dentro de cada individuo) y between (diferencias entre las medias individuales).
Pooled OLS ignora la estructura de panel y es inconsistente si \(\alpha_i\) correlaciona con los regresores. Efectos fijos (el estimador within) elimina \(\alpha_i\) restando las medias temporales; es consistente siempre, pero no puede estimar el efecto de variables invariantes en el tiempo. Efectos aleatorios supone \(\text{Cov}(\alpha_i, \mathbf{x}_{it}) = 0\) y combina variación within y between; es más eficiente cuando el supuesto se cumple, pero inconsistente cuando no.
El test de Hausman compara los dos estimadores y guía la elección. En caso de duda, el consejo es conservador: usar efectos fijos. Los diagnósticos básicos incluyen el test F y Breusch-Pagan (existencia de efectos individuales), Wooldridge (autocorrelación) y la recomendación universal de reportar errores clustered por individuo.
5.15 Funciones esenciales de R para panel
Los scripts completos de este capítulo y los casos prácticos están disponibles en el repositorio del manual:
https://github.com/carlanta/MicroEconometrics
A continuación se describen las funciones de R más relevantes para el análisis abordado en este capítulo.
5.15.1 plm() — Estimación de modelos de panel
La función plm() del paquete plm es la herramienta central para estimar todos los modelos de panel en R. Necesita un pdata.frame que identifique los índices de individuo y tiempo.
library(plm)
pdata <- pdata.frame(datos, index = c("id", "year"))
mod <- plm(y ~ x1 + x2, data = pdata, model = "within")El parámetro model determina el tipo de estimador. Los valores posibles son "pooling" (Pooled OLS, ignora la estructura de panel), "within" (efectos fijos, elimina los efectos individuales mediante la transformación within), "random" (efectos aleatorios, estimador GLS que combina variación within y between), "fd" (primeras diferencias) y "between" (estimador entre medias individuales). El parámetro effect controla la dimensión de los efectos: "individual" (por defecto), "time" o "twoways" (efectos bidireccionales individuo + tiempo).
5.15.2 fixef() y ranef() — Efectos individuales estimados
Una vez estimado un modelo de efectos fijos, fixef() extrae los interceptos individuales estimados \(\hat{\alpha}_i\). Para modelos de efectos aleatorios, ranef() calcula las predicciones BLUP (Best Linear Unbiased Predictor) de los efectos aleatorios.
fixef(modelo_fe) # vector con alpha_i de cada individuo
ranef(modelo_re) # predicciones de los efectos aleatoriosEl resultado de fixef() es un vector con nombre donde cada elemento corresponde a un individuo. El de ranef() es análogo pero para los efectos aleatorios predichos.
5.15.3 phtest() — Test de Hausman
El test de Hausman decide entre efectos fijos y efectos aleatorios comparando si los coeficientes de ambos estimadores difieren significativamente.
phtest(modelo_fe, modelo_re)Recibe como argumentos los dos modelos estimados previamente con plm(). Si el p-valor es menor que 0.05, se rechaza la hipótesis nula (EA es consistente) y se debe usar efectos fijos. Si es mayor, efectos aleatorios es adecuado y más eficiente.
5.15.4 pFtest() y plmtest() — Tests de efectos individuales
Estos tests verifican si existen efectos individuales significativos, es decir, si Pooled OLS es suficiente o si necesitamos un modelo de panel.
pFtest(modelo_fe, modelo_pooled) # Test F
plmtest(modelo_pooled, type = "bp") # Test LM de Breusch-PaganpFtest() realiza un test F que compara el modelo de efectos fijos con el Pooled. Requiere ambos modelos como argumentos. plmtest() realiza el test de multiplicadores de Lagrange de Breusch-Pagan, que contrasta \(H_0: \sigma_\alpha^2 = 0\). El parámetro type = "bp" indica la versión Breusch-Pagan; otra opción habitual es "honda".
5.15.5 pwartest() — Test de autocorrelación de Wooldridge
Contrasta la presencia de autocorrelación de primer orden en los errores idiosincráticos del modelo de panel.
pwartest(modelo_fe)Si el p-valor es inferior a 0.05, existe autocorrelación serial y los errores estándar convencionales del estimador within son incorrectos. En ese caso es imprescindible usar errores clustered.
5.15.6 coeftest() con vcovHC() — Errores robustos clustered
La recomendación estándar es reportar siempre errores clustered por individuo, que corrigen simultáneamente por heterocedasticidad y autocorrelación.
library(lmtest); library(sandwich)
coeftest(modelo, vcov = vcovHC(modelo, type = "HC1",
cluster = "group"))La función coeftest() del paquete lmtest recalcula los errores estándar usando la matriz de varianzas-covarianzas robusta que proporciona vcovHC() del paquete sandwich. El parámetro type = "HC1" aplica la corrección por grados de libertad de MacKinnon y White. El parámetro cluster = "group" indica que el agrupamiento es por individuo (la unidad transversal del panel).
Grunfeld, Yehuda. 1958. The Determinants of Corporate Investment.
Hausman, Jerry A. 1978. “Specification Tests in Econometrics.” Econometrica 46 (6): 1251–71.